

A importância do pré-processamento para melhorar a eficiência e a facilidade do processo de mineração de dados
A crescente quantidade de dados disponíveis atualmente, muitas vezes medida em zetabytes, exige a implementação de métodos eficientes de pré-processamento para viabilizar análises e mineração de dados. Além do volume avassalador, as fontes de informação frequentemente não são padronizadas, o que torna a integração e análise ainda mais desafiadoras.
Dados de baixa qualidade, contendo problemas como ruídos, valores faltantes ou discrepâncias, podem comprometer seriamente a eficácia de modelos preditivos e análises. Dessa forma, sem dados adequadamente preparados, os resultados se tornam inconsistentes e pouco confiáveis, reduzindo o valor das iniciativas baseadas em dados.
Por que o Pré-Processamento de Dados é Essencial?
Os problemas mais comuns encontrados ao trabalhar com dados incluem valores ausentes, informações incorretas e discrepâncias entre atributos. Muitas bases de dados também apresentam valores categóricos que não são compatíveis com determinados algoritmos, ou atributos com diferentes escalas que precisam ser ajustados para ter igual relevância no processo.
Além disso, a alta dimensionalidade em algumas bases pode dificultar a análise, exigindo redução para melhorar a eficiência.
Em cenários onde os recursos computacionais ou o tempo são limitados, é igualmente importante considerar a redução do volume de exemplos para tornar a mineração viável.
Etapas do Pré-Processamento de Dados
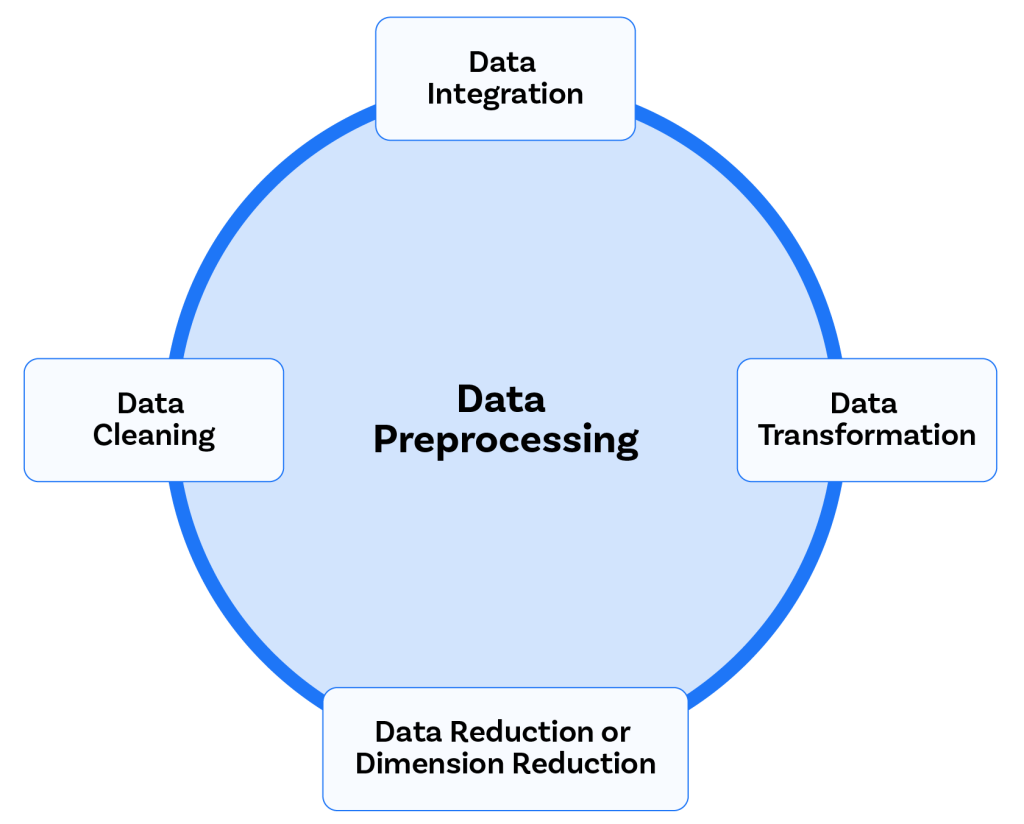
O pré-processamento de dados desempenha um papel essencial, envolvendo etapas como limpeza, integração, transformação e redução.
Limpeza de Dados: Resolvendo Valores Ausentes e Outliers
A limpeza dos dados é crucial para resolver problemas relacionados a valores ausentes, ruídos e outliers, além de corrigir inconsistências.
Para lidar com valores ausentes, podem ser utilizados métodos como preenchimento manual, cálculo da média ou até técnicas mais avançadas, como regressão. Já para suavizar ruídos ou eliminar outliers, ferramentas como alisamento, regressão ou clustering são amplamente aplicadas.
Erros gerados na entrada ou integração dos dados podem ser corrigidos manualmente ou automatizados via scripts, dependendo da complexidade e do volume dos dados.
Integração de Dados: Unificando Fontes de Informação
A integração de dados é outro passo fundamental, especialmente quando as informações vêm de múltiplas fontes, como bancos de dados, data warehouses ou arquivos de texto. Este processo busca unificar diferentes fontes em uma base coerente, reduzindo redundâncias e inconsistências.
Entretanto, pode haver desafios como nomes divergentes para atributos iguais, valores conflitantes devido a escalas distintas ou discrepâncias na representação de dados. Para resolver esses problemas, são utilizados metadados e tabelas de conversão, garantindo que as informações integradas estejam alinhadas.
Transformação de Dados: Normalização e Codificação Categórica
Na transformação dos dados, o foco está em adequar as informações às exigências dos algoritmos de mineração. A normalização, por exemplo, é amplamente usada para alinhar variáveis com diferentes unidades e distribuições.
Técnicas como min-max, z-score ou escala decimal ajudam a uniformizar os dados, garantindo que todos os atributos tenham peso equivalente no processamento. Já para dados categóricos, métodos como o one-hot encoding transformam categorias em matrizes binárias, facilitando a utilização em algoritmos que requerem entradas numéricas.
Redução de Dados: Otimizando Volume e Dimensionalidade
A etapa de redução dos dados tem como objetivo diminuir tanto o volume quanto a dimensionalidade, tornando o processamento mais eficiente sem sacrificar a qualidade da informação.
Essa redução pode ser feita por meio da compressão de características similares ou pela discretização, que agrupa valores contínuos em categorias, simplificando a análise e otimizando os algoritmos.
Benefícios do Pré-Processamento para Modelos Preditivos
Além de melhorar a eficiência computacional e reduzir o tempo de processamento, o pré-processamento de dados também impacta diretamente a qualidade dos resultados. Dados bem preparados aumentam a precisão dos modelos preditivos e a relevância dos padrões descobertos.
Por outro lado, dados mal processados podem levar a erros, vieses ou até ao fracasso completo do projeto. Casos reais mostram que projetos bem-sucedidos, especialmente em áreas como saúde, finanças e comércio eletrônico, são frequentemente sustentados por um bom trabalho de pré-processamento.
Casos de Sucesso no Uso do Pré-Processamento de Dados
Portanto, o pré-processamento de dados é indispensável para garantir que análises e modelos preditivos sejam eficazes e confiáveis. Embora seja um processo trabalhoso, os benefícios superam os desafios, resultando em análises mais precisas e insights valiosos.
Desse modo, negligenciar essa etapa pode comprometer todo o processo de mineração, levando a conclusões errôneas ou inutilizáveis. Assim, investir em técnicas robustas de pré-processamento é essencial para obter o máximo valor dos dados disponíveis.
Referências:
AGGARWAL, C. C. “Data Mining: The Textbook”. Springer, 2015.
Artigo foi escrito por Bruno Moreira, cientista de dados na Oper.


