Artigo feito em colaboração com Bethânia Kelly
Introdução
A Arquitetura de Medalhão é uma abordagem estruturada para o gerenciamento de dados que organiza as informações em camadas sequenciais, frequentemente denominadas Bronze, Silver e Gold. Essas camadas representam diferentes níveis de processamento e refinamento dos dados: a camada Bronze armazena os dados brutos, a Silver contém dados pré-processados e limpos, enquanto a camada Gold guarda os dados prontos para análise e consumo final.
A Arquitetura de Medalhão foi inicialmente desenvolvida para responder à necessidade de escalabilidade e eficiência em ambientes de big data, onde o volume e a complexidade dos dados exigem uma abordagem metódica e organizada. Com o avanço das tecnologias de armazenamento e processamento, como o Apache Spark e o Delta Lake, essa arquitetura evoluiu, tornando-se um padrão de referência para pipelines de dados modernos.
Entre as características mais marcantes da Arquitetura de Medalhão está a sua capacidade de garantir a qualidade e a consistência dos dados ao longo do pipeline de processamento. Ao dividir os dados em camadas, a arquitetura facilita o rastreamento de alterações, a implementação de políticas de governança e a otimização do desempenho do sistema. O principal objetivo é fornecer uma estrutura clara e escalável que suporte desde a ingestão de dados brutos até a geração de insights valiosos, atendendo às necessidades de diferentes stakeholders dentro da organização.
Motivações para a Arquitetura de Medalhão
Em um ambiente de dados moderno, a confiança nos dados é essencial para decisões estratégicas e operacionais. Com o aumento da complexidade e do volume de dados, garantir a precisão, consistência e disponibilidade das informações tornou-se um desafio significativo. Organizações precisam de arquiteturas que possam lidar não apenas com grandes quantidades de dados, mas também com a necessidade de integridade e rastreabilidade em todos os estágios do pipeline.
Arquiteturas tradicionais, muitas vezes monolíticas, enfrentam dificuldades em escalar e manter a qualidade dos dados à medida que o volume e a complexidade aumentam. Essas arquiteturas tendem a misturar dados brutos e processados em uma única camada, dificultando a rastreabilidade e a governança de dados. Além disso, a falta de segmentação clara entre diferentes estágios de processamento pode levar a problemas de desempenho e aumento da complexidade na manutenção dos sistemas.
A Arquitetura de Medalhão resolve esses desafios ao segmentar os dados em camadas distintas: Bronze, Silver e Gold. Essa segmentação permite uma organização mais eficiente, onde dados brutos são isolados em uma camada dedicada (Bronze), dados pré-processados e validados são armazenados na camada Silver, e dados prontos para consumo analítico residem na camada Gold. Esse modelo melhora a governança de dados, facilita a rastreabilidade e otimiza o desempenho, permitindo que as organizações escalem seus sistemas de dados sem comprometer a qualidade ou a eficiência. Além disso, a arquitetura oferece flexibilidade para implementar políticas de qualidade de dados e auditoria em cada camada, garantindo que os dados sejam confiáveis e prontos para suportar decisões críticas.
Componentes da Arquitetura de Medalhão
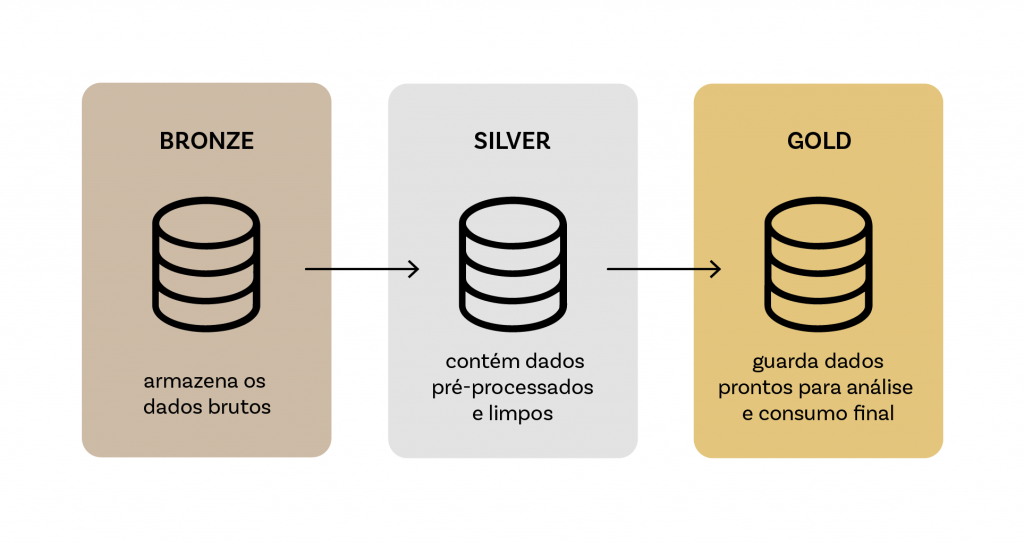
A camada Bronze é a base da Arquitetura de Medalhão, onde os dados são armazenados em seu estado bruto, exatamente como foram ingeridos das fontes originais. A principal importância desta camada reside em sua capacidade de preservar a integridade dos dados originais, garantindo que nenhuma informação seja perdida durante o processo de ingestão. Ela serve como um repositório histórico, permitindo que os dados possam ser revisitados ou reprocessados conforme necessário. Exemplos de dados armazenados na camada Bronze incluem logs de servidores, dados de sensores IoT e transações brutas de e-commerce.
Na camada Silver, os dados brutos passam por processos de limpeza, normalização e transformação para remover inconsistências, duplicidades e valores nulos. Este estágio é fundamental para preparar os dados para análises mais detalhadas, garantindo que eles estejam em um formato consistente e utilizável. A camada Silver adiciona valor ao estruturar os dados de maneira que eles possam ser facilmente integrados e analisados, resultando em uma base de dados que é tanto confiável quanto pronta para suportar aplicações analíticas. Exemplo de operações nesta camada incluem a normalização de formatos de data, correção de erros de entrada e junção de tabelas relacionais.
A camada Gold é onde os dados transformados e limpos são agregados e integrados para suportar análises avançadas e geração de relatórios. Nesta etapa, os dados são modelados e enriquecidos para fornecer insights diretamente utilizáveis por analistas e tomadores de decisão. A camada Gold é otimizada para consultas rápidas e é frequentemente utilizada para dashboards, relatórios financeiros e análises preditivas. Casos de uso típicos incluem a criação de modelos de machine learning, análise de comportamento de clientes e relatórios de desempenho de negócios.
Processos e Ferramentas na Implementação

Os pipelines de ETL (Extract, Transform, Load) e ELT (Extract, Load, Transform) são fundamentais para a implementação da Arquitetura de Medalhão. No contexto de dados modernos, ferramentas como Apache Spark e Databricks são amplamente utilizadas para construir esses pipelines, permitindo o processamento em larga escala e a transformação eficiente dos dados. A escolha entre ETL e ELT depende da infraestrutura e dos requisitos específicos do projeto; o ELT é geralmente preferido em ambientes de big data devido à sua flexibilidade e desempenho. As práticas recomendadas para pipelines de dados incluem o uso de operações idempotentes, o tratamento adequado de erros e a implementação de testes automatizados para garantir a consistência e a qualidade dos dados ao longo do pipeline.
O armazenamento de dados na Arquitetura de Medalhão pode ser realizado em diferentes tipos de infraestrutura, sendo os Data Lakes e os Data Warehouses as opções mais comuns. Data Lakes são ideais para armazenar grandes volumes de dados brutos e semi-estruturados, enquanto Data Warehouses são otimizados para consultas analíticas rápidas em dados estruturados. A escolha entre armazenamento on-premise e na cloud (nuvem) depende de fatores como custo, escalabilidade e requisitos de conformidade. A cloud é frequentemente preferida devido à sua flexibilidade e capacidade de escalar de acordo com a demanda, com serviços como Amazon S3, Google Cloud Storage e Azure Data Lake sendo populares entre as empresas que adotam a Arquitetura de Medalhão.
A governança de dados é crucial em cada camada da Arquitetura de Medalhão para garantir que os dados sejam gerenciados de forma segura, consistente e conforme as normas regulatórias. Isso inclui a implementação de políticas de acesso, auditorias de uso e monitoramento contínuo da qualidade dos dados. Ferramentas como Apache Ranger e Databricks’ Unity Catalog são frequentemente usadas para definir e aplicar políticas de governança, garantindo que apenas usuários autorizados possam acessar ou modificar os dados. Além disso, práticas como a criação de catálogos de dados, documentação rigorosa e a automação de auditorias são essenciais para manter a integridade e a segurança dos dados em toda a arquitetura.
Vantagens e Desvantagens da Arquitetura de Medalhão
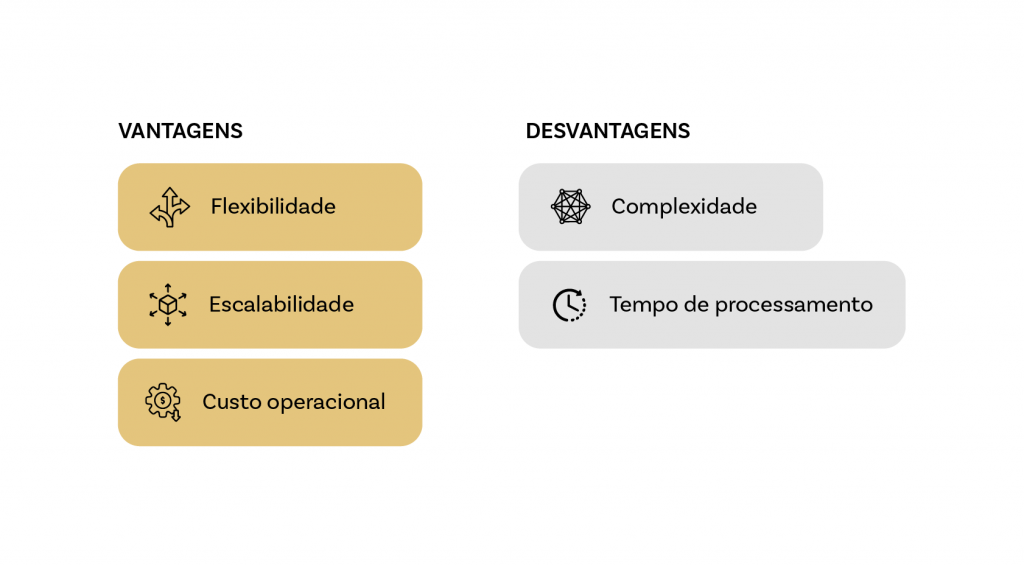
Vantagens
A Arquitetura de Medalhão é altamente flexível, permitindo que as organizações adaptem seus pipelines de dados de acordo com as necessidades específicas do negócio. Com a separação clara entre as camadas Bronze, Silver e Gold, diferentes tipos de dados podem ser processados em diferentes níveis de granularidade, facilitando o tratamento de dados brutos até análises refinadas. Essa flexibilidade permite que as empresas adicionem ou modifiquem etapas no pipeline sem interromper o fluxo geral de dados.
Outra grande vantagem é sua escalabilidade. Projetada para lidar com grandes volumes de dados, essa arquitetura pode ser facilmente expandida à medida que o volume e a variedade de dados aumentam. Ferramentas como Apache Spark e ambientes em cloud, como Databricks, suportam o processamento paralelo em larga escala, garantindo que o sistema possa crescer sem comprometer o desempenho ou a eficiência.
Do ponto de vista do custo, a Arquitetura de Medalhão pode ser bastante eficiente. Ao adotar uma abordagem em camadas, as organizações podem armazenar grandes volumes de dados brutos a um custo relativamente baixo na camada Bronze, enquanto concentram recursos de computação mais caros nas camadas Silver e Gold, onde os dados já foram filtrados e refinados. Além disso, o uso de soluções de armazenamento em cloud permite o pagamento por uso, otimizando os custos operacionais.
Desvantagens
A complexidade é uma das principais desvantagens. A implementação de um sistema de dados em camadas requer um planejamento cuidadoso e uma infraestrutura robusta para garantir que os dados fluam corretamente entre as camadas. A criação e manutenção de pipelines de ETL/ELT, a integração de ferramentas diversas e a configuração de políticas de governança podem exigir uma equipe técnica especializada e recursos significativos.
Outro desafio é o tempo de processamento. Como os dados precisam passar por várias camadas antes de estarem prontos para o consumo final, isso pode introduzir latência no pipeline. Em cenários onde a análise em tempo real é crucial, essa latência pode ser um impedimento significativo, exigindo otimizações ou até mesmo a adoção de uma abordagem híbrida que combine a Arquitetura de Medalhão com técnicas de processamento em tempo real.
Comparação com Outras Arquiteturas de Dados
Os Data Warehouses tradicionais são projetados para armazenar dados estruturados que foram cuidadosamente limpos e organizados, permitindo consultas rápidas e análises complexas. Eles são altamente otimizados para operações de leitura e são usados principalmente para relatórios empresariais e análises históricas. No entanto, eles têm limitações em termos de flexibilidade e custo, especialmente quando se trata de lidar com grandes volumes de dados brutos ou semiestruturados. Comparado à Arquitetura de Medalhão, que oferece camadas distintas para diferentes estágios de processamento de dados, os Data Warehouses tendem a ser menos adequados para cenários que exigem escalabilidade e manipulação de dados variados.
Um Data Lake é um repositório centralizado que permite armazenar grandes volumes de dados em seu formato original, sejam eles estruturados, semiestruturados ou não estruturados. Essa arquitetura é altamente escalável e oferece flexibilidade para armazenar dados brutos, o que é ideal para análise de big data e aprendizado de máquina. No entanto, um Data Lake pode se transformar em um “lago de dados sujos” sem uma governança adequada, dificultando a extração de insights valiosos. A Arquitetura de Medalhão melhora o conceito de Data Lake ao introduzir camadas estruturadas, como Bronze, Silver e Gold, para organizar e refinar os dados ao longo do pipeline, o que facilita o acesso e o uso dos dados.
O Data Lakehouse é uma arquitetura emergente que combina os pontos fortes dos Data Lakes e dos Data Warehouses. Ele permite o armazenamento de dados brutos e semiestruturados como em um Data Lake, enquanto oferece as capacidades de gerenciamento, governança e otimização de consultas de um Data Warehouse. A Arquitetura de Medalhão pode ser vista como uma forma específica de Data Lakehouse, onde os dados são organizados em camadas para melhorar a acessibilidade e a qualidade, mantendo a flexibilidade e a escalabilidade de um Data Lake. O Data Lakehouse é ideal para organizações que precisam de uma solução única para processamento de dados brutos e análises estruturadas.
A escolha da Arquitetura de Medalhão é ideal quando uma organização precisa lidar com uma grande variedade de dados em diferentes estágios de maturidade e processamento. Ela é particularmente adequada para ambientes onde a escalabilidade é uma prioridade, mas onde também é essencial manter a qualidade e a organização dos dados ao longo do pipeline. Essa arquitetura é preferível em projetos que requerem a integração de grandes volumes de dados brutos e semiestruturados, como logs de eventos, dados de sensores ou fluxos de redes sociais, com a necessidade de transformar esses dados em insights prontos para consumo analítico. Em contraste, Data Warehouses tradicionais podem ser mais apropriados para ambientes onde a maioria dos dados já é estruturada e as análises requerem desempenho altamente otimizado, enquanto os Data Lakes são mais indicados para cenários onde a principal preocupação é o armazenamento massivo e flexível de dados em seus formatos originais.
Considerações Finais
À medida que o volume e a variedade de dados continuam a crescer, a Arquitetura de Medalhão tende a evoluir para lidar com novos desafios e aproveitar tecnologias emergentes. Uma tendência futura significativa é a integração ainda mais profunda com soluções de inteligência artificial e aprendizado de máquina, onde as camadas Gold serão cada vez mais utilizadas para alimentar modelos avançados de previsão e análise em tempo real. Além disso, com o avanço da computação em nuvem, espera-se que a Arquitetura de Medalhão se torne mais automatizada, com a adoção de práticas como DataOps e o uso de plataformas serverless para otimizar custos e recursos. A evolução da governança de dados, impulsionada por regulamentações mais rigorosas, também será uma área de foco, garantindo que as empresas possam gerenciar seus dados com maior transparência e controle.
Para as empresas que estão considerando a implementação da Arquitetura de Medalhão, algumas dicas podem ser valiosas. Primeiro, é essencial começar com uma análise detalhada das necessidades e capacidades da organização. Compreender o tipo de dados que a empresa lida e os resultados que deseja alcançar ajudará a estruturar corretamente as camadas Bronze, Silver e Gold. Investir em ferramentas e tecnologias que suportam a arquitetura, como Apache Spark, Databricks e plataformas de nuvem, pode facilitar a implementação e garantir escalabilidade. Além disso, as empresas devem priorizar a governança de dados desde o início, estabelecendo políticas claras para o acesso, controle de qualidade e segurança dos dados. Finalmente, adotar uma abordagem iterativa e ágil para a implementação pode ajudar a ajustar o sistema com base em feedbacks contínuos. Isso garante que a arquitetura evolua de acordo com as necessidades do negócio.
Referências bibliográficas
https://databricks.com/solutions/data-lake
https://towardsdatascience.com/understanding-the-medallion-architecture
Gorton, I., & Klein, J. (2015). Architecture Techniques for Data Lakes. Proceedings of the 2015 12th Working IEEE/IFIP Conference on Software Architecture, 2015.
Sawant, N., & Shah, H. (2013). Big Data Application Architecture Q&A: A Problem-Solution Approach. Apress.
Hodeghatta, U. R., & Nayak, U. (2018). Big Data Analytics: Frameworks, Techniques, and Applications. Springer.
Muller, N. (2017). Data Lake Architecture: Designing the Data Lake and Avoiding the Garbage Dump. O’Reilly Media.
Zaharia, M., & Wendell, P. (2020). Spark: The Definitive Guide: Big Data Processing Made Simple. O’Reilly Media.
Henschen, D. (2021). Data Lakehouse: Bridging the Gap Between Data Lakes and Data Warehouses. TDWI. Disponível em: https://tdwi.org.
Armbrust, M., et al. (2021). Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. CIDR 2021.
Gade, R. (2020). DataOps: The Agile Data Methodology. Springer.