Artigo escrito por Paula Gouveia
A regressão logística é uma técnica estatística poderosa, especialmente útil para problemas de classificação binária. Neste artigo, vamos demonstrar como implementar um modelo simples de regressão logística em Python, utilizando dados reais para prever a ocorrência de doenças coronárias (CHD) com base na idade dos pacientes.
Introdução
A regressão logística é amplamente empregada em diversas áreas, particularmente na saúde, para prever resultados binários, como a presença ou ausência de uma condição. O objetivo deste estudo é analisar a relação entre a idade de um indivíduo e a probabilidade de desenvolver doença coronária, com base em uma amostra de 100 pessoas.
Ao longo deste artigo, exploraremos todo o processo de análise: desde o download e preparação dos dados até a análise exploratória, construção e interpretação do modelo de regressão logística.
Instalação e Importação das Bibliotecas
Primeiro, precisamos garantir que temos todas as bibliotecas necessárias instaladas. Caso não tenha alguma delas, você pode instalá-las usando o pip, como no exemplo abaixo:
pip install statsmodelsEm seguida, importamos as bibliotecas:
import os
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.formula.api import
from rpy2.robjects import
from rpy2.robjects import
pandas2ri.activate()Carregamento dos Dados
Os dados utilizados neste estudo estão armazenados em um arquivo RDA disponível no GitHub. Vamos fazer o download e carregar esses dados:
# URL do arquivo .rdaurl = "https://github.com/lbraglia/aplore3/raw/master/data/chdage.rda"
local_file = "chdage.rda"
Caso o arquivo não esteja no computador, utilizamos o seguinte código para realizar o download automaticamente:
# Baixando o arquivo .rda
if not os.path.exists(local_file):
response = requests.get(url)
with open(local_file, 'wb') as f:
f.write(response.content)
Além disso, carregamos o arquivo .rda usando rpy2:
# Carregando o arquivo .rda usando rpy2
r_data = r['load'](local_file)
chd_dados = pandas2ri.rpy2py(r[r_data[0]])
# Visualiza as primeiras linhas
print(chd_dados.head())Preparação dos Dados
Uma inspeção inicial nos dados mostra que a variável CHD contém os valores 1 e 2. No entanto, para o modelo de regressão logística, precisamos de valores 0 e 1.
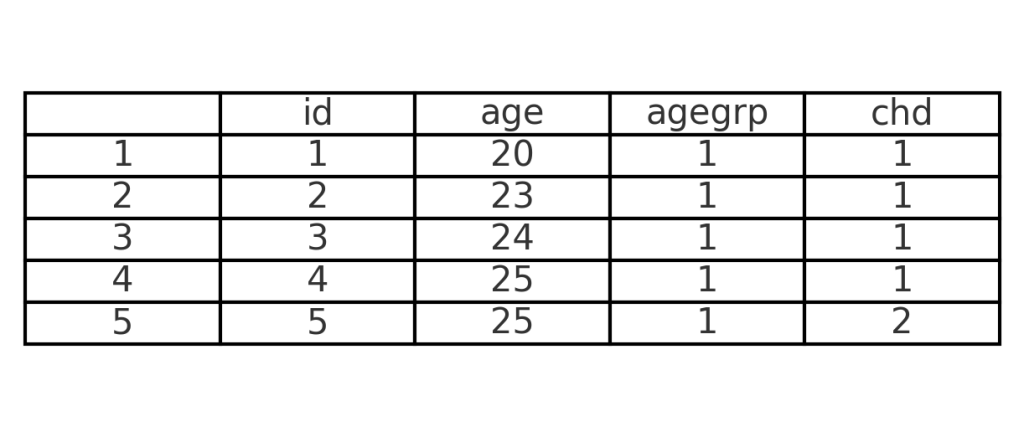
Vamos fazer essa conversão:
# Visualiza as primeiras linhas
print(chd_dados.head())# Substituir os valores 2 por 1 e os valores 1 por 0chd_dados['chd'] = chd_dados['chd'].replace({1: 0, 2: 1})# Medida resumo dos dados
print(chd_dados.describe())
Nossa base de dados contém 100 observações e 4 variáveis:
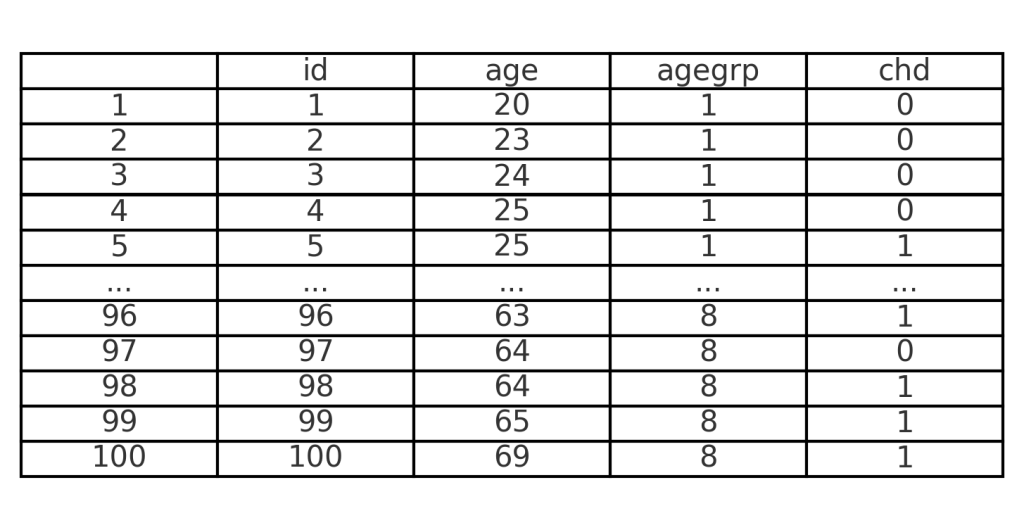
- ID: identificação do indivíduo
- age: idade em anos
- agegrp: categoria de idade
- chd: presença (1) ou ausência (0) de doença coronária
Analisando as estatísticas descritivas, observamos que:
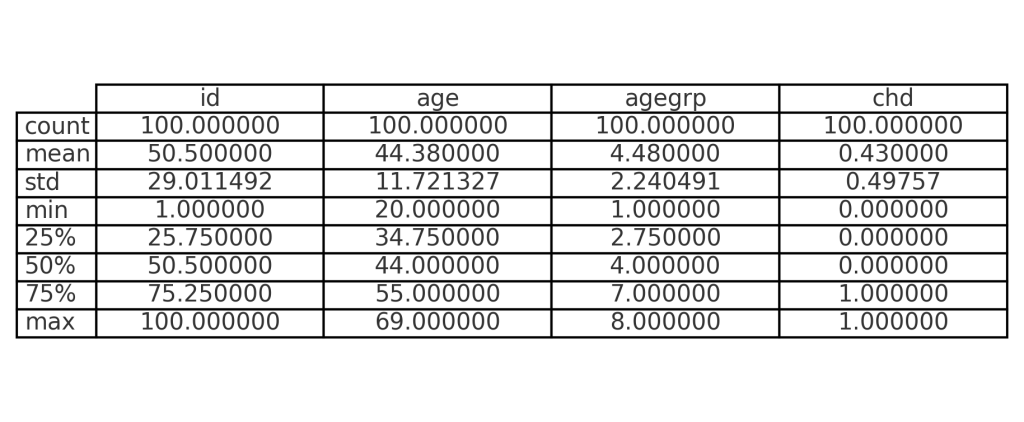
- Para a variável age: a idade mínima é 20 anos e a máxima 69 anos, com média de 44,38 anos
- 50% dos indivíduos têm idade igual ou inferior a 44 anos
- 75% dos indivíduos têm idade igual ou inferior a 55 anos
- Para a variável CHD: 57 indivíduos não apresentam a doença (valor 0) e 43 apresentam (valor 1)
Análise Exploratória dos Dados
Uma forma eficaz de visualizar a relação entre idade e presença de doença coronária é através de um gráfico de dispersão:
sns.scatterplot(data=chd_dados, x='age', y='chd', alpha=0.6)
plt.title("Gráfico de dispersão entre idade e doença coronária")
plt.xlabel("Idade")
plt.ylabel("CHD (0 = Ausência, 1 = Presença)")
plt.show()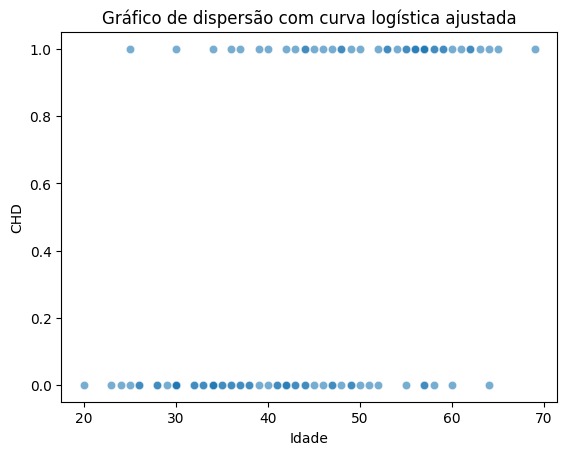
Gráfico de dispersão entre idade e CHD
Neste gráfico, cada ponto representa um indivíduo, e podemos observar a tendência de aumento na ocorrência de CHD com o avanço da idade. Além disso, os pontos na parte superior (valor 1) indicam presença de doença coronária, enquanto os pontos na parte inferior (valor 0) indicam ausência da doença.
Ajuste do Modelo de Regressão Logística
Agora vamos ajustar um modelo de regressão logística simples, usando a função logit da biblioteca statsmodels:
modelo = logit("chd ~ age", data=chd_dados).fit()
print(modelo.summary())O resultado mostrará um resumo completo com os coeficientes, erros padrão, valores-p e outras estatísticas importantes.

Vamos analisar os principais resultados:
- O intercepto (β₀) é aproximadamente -5,30. Este valor não tem uma interpretação prática direta para o nosso problema.
- O coeficiente da idade (β₁) é aproximadamente 0,11. O fato de ser positivo indica que, à medida que a idade aumenta, as chances de ocorrência da doença coronária também aumentam.
- Os p-valores são estatisticamente significantes (menores que 0,05), o que indica que as variáveis têm relevância para o modelo proposto.
Interpretação dos Resultados
O modelo de regressão logística fornece os resultados dos estimadores na forma logarítmica. Para facilitar a interpretação, vamos calcular o odds ratio (razão de chances):
odds_ratio = np.exp(modelo.params)
print("Odds Ratio:\n", odds_ratio)O odds ratio para a idade é aproximadamente 1,11, o que significa que, a cada ano adicional de idade, as chances de ocorrência de CHD aumentam 1,11 vezes.
Podemos também calcular a variação percentual:
variacao_percentual = (odds_ratio['age'] - 1) * 100
print(f"Variação percentual: {variacao_percentual:.2f}%")Temos, como interpretação desse resultado, que, a cada ano de aumento na idade, as chances de ter CHD aumentam aproximadamente 11,73%.
Para entender a incerteza dos nossos coeficientes, vamos construir um intervalo de confiança de 95%:
conf_int = modelo.conf_int()
conf_int_exp = np.exp(conf_int)
conf_int_exp.columns = ['2.5%', '97.5%']
print("Intervalo de Confiança (95%):\n", conf_int_exp)O intervalo de confiança para o odds ratio da idade vai de aproximadamente 1,06 a 1,17, o que nos dá confiança de que o verdadeiro valor do parâmetro está dentro desse intervalo.
Predições do Modelo
Por fim, vamos fazer uma predição usando a idade média da amostra:
idade_media = chd_dados['age'].mean()
media = pd.DataFrame({'age': [idade_media]})
media['pred_prob'] = modelo.predict(media)
print("Predição para idade média:\n", media)Esse resultado portanto nos mostra que para a idade média da amostra (44,38 anos), há uma probabilidade de 40,44% de um indivíduo ter doença coronária, de acordo com o modelo ajustado.
Conclusão
Neste artigo, exploramos a implementação de um modelo de regressão logística simples em Python para prever a ocorrência de doenças coronárias com base na idade do paciente. Vimos que a idade é um fator significativo para prever CHD, com um aumento de aproximadamente 11,73% nas chances de ocorrência da doença a cada ano adicional de idade.
Este tipo de análise é fundamental em estudos epidemiológicos e pode ser expandido para incluir mais variáveis explicativas, como pressão arterial, níveis de colesterol, tabagismo, entre outros fatores de risco conhecidos para doenças cardiovasculares.
Para futuros estudos, poderíamos:
- Incluir mais variáveis explicativas para um modelo de regressão logística múltipla
- Dividir os dados em conjuntos de treino e teste para validação do modelo
- Explorar outras métricas de avaliação do modelo, como curva ROC, área sob a curva (AUC), matriz de confusão, etc.
- Comparar o desempenho com outros algoritmos de classificação
A regressão logística continua sendo uma ferramenta poderosa e interpretável para problemas de classificação binária na área de saúde e em muitos outros campos.
Referências Bibliográficas
AGRESTI, A. An introduction to categorical data analysis. 2. ed. New York: J. Wiley & Sons, 2007. 394 p.
AGRESTI, A. Categorical data analysis. 3. ed. New York: J. Wiley & Sons, 2013. 714 p.
GIOLO, S. R. Introdução à análise de dados categóricos com aplicações. São Paulo: Blucher, 2017. 256 p.
HOSMER, D.; LEMESHOW, S.; STURDIVANT, R. Applied Logistic Regression. 3. ed. New York: J. Wiley & Sons, 2013. 528 p.