

Artigo escrito por Gabriel Lafetá
O trabalho do RH dentro de uma empresa tem se tornado cada dia mais importante. Dessa forma, talvez os profissionais de ciência de dados e negócios não saibam o quão oneroso pode ser a busca por um profissional que preencha perfeitamente todos os requisitos de uma vaga anunciada pela sua empresa. Felizmente, a tecnologia já evoluiu a ponto de nos conceder fortes aliados nas buscas otimizadas, principalmente quando combinamos o Processamento de Linguagem Natural (NLP) com métodos de geometria analítica como a Similaridade de cossenos.
Nesse sentido, entende-se NLP como o segmento do aprendizado de máquina que traduz linguagem humana em valores estatísticos, que possuem enorme valor para análises de frequências de termos repetidos, sentimentos expressos e similaridade com outros conteúdos em grandes blocos de texto. Naturalmente, esse método é fortemente embasado por princípios matemáticos, como de geometria analítica, no caso da similaridade de cossenos, para então medir a semelhança entre duas sentenças convertidas em vetores.
A similaridade de cossenos pode ser encontrada em qualquer livro universitário de geometria analítica e é amplamente utilizada para medir a semelhança entre dois vetores por via do cosseno do ângulo compreendido entre os dois:
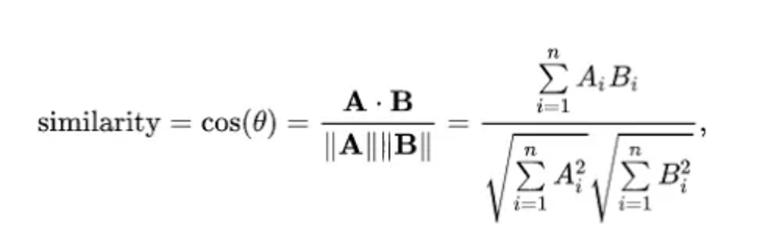
Sendo assim, será demonstrado abaixo a aplicação desses conceitos em um case prático envolvendo a tarefa de RH mencionada acima.
Estudo de Caso
Imagine então que seja possível para o RH automatizar a busca por perfis profissionais com as melhores características para as suas vagas, utilizando recursos do perfil do LinkedIn como descrição, cargos anteriores e habilidades e compará-los com uma única sentença do tipo “Procuro um profissional dedicado com capacidade analítica e experiência no varejo, que domine Pyhton, SQL, Excel, PySpark e algoritmos de machine learning”. Interessante, não? Mas para isso, primeiramente precisamos modelar nosso problema da obtenção de dados aos cálculos das métricas.
Os dados utilizados foram extraídos do Apify, um site que oferta web scrapers com um click com períodos de teste grátis. No caso, utilizamos o Linkedin Companies & Profiles Bulk Scraper e pelos próprios parâmetros é possível colocar alguns filtros de assunto e localidade, portanto foi utilizado “Data Science” e “Ciência de dados” como filtro de assunto e “Brasil” como filtro de localidade. Foram extraídos 2955 perfis, valor que pode ser alterado dependendo da disponibilidade e preferência do usuário.
Em seguida, foram importados para o IDE python os pacotes necessários. Para o uso do NLP em si o pacote escolhido foi o NLTK, amplamente difundido no python.
import pandas as pd
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.stem import RSLPStemmer
import re
from datetime import datetime
from collections import Counter
import matplotlib.pyplot as plt
from unidecode import unidecode
from scipy.spatial import distanceExtração de valor analítico
Primeiramente, existem três processos a serem realizados em um bloco de texto para extrair valor analítico: Stemmização, que consiste em utilizar as raízes das palavras (“cien” no lugar de cientista ou ciência), remoção de stop words, ou seja, remover palavras sem valor analítico com conectivos e artigos e a tokenização que divide a sentença em termos individuais.
A função abaixo realiza essas tarefas para a descrição do candidato:
def tratamento_palavras(col):
lista_descricoes_tratadas = []
stemmer = RSLPStemmer()
# Para cada linha no dataset aplicará o tratamento
for index, row in base_linkedin.iterrows():
bloco = row[col]
bloco_texto = str(bloco)
# Removendo caracteres especiais e tokenizando as palavras
tokens = word_tokenize(re.sub(r'[^\w\s]', '', bloco_texto), language='portuguese')
# Removendo as stop words e stemmizando
palavras_stemmizadas = [stemmer.stem(unidecode(token).lower()) for token in tokens if token not in sem_stop_words]
lista_descricoes_tratadas.append(palavras_stemmizadas)
# Criar um DataFrame com uma coluna chamada 'Tokens' que contém as listas
df_stem = pd.DataFrame({'Tokens': lista_descricoes_tratadas})
return df_stemO web scraper também extrai as habilidades que o potencial candidato colocou no seu perfil, assim também precisaremos criar uma função para analisa-las. No caso das habilidades do candidato, elas estão distribuídas ao longo de 20 colunas nomeadas f”skills/{i}” onde i varia de 0 a 19. Além disso, a função concatena os 20 valores em uma coluna e aplica os passos para introdução do NLP.
def tratamento_skill():
bag_of_skills = []
stemmer = RSLPStemmer()
for index, row in base_linkedin.iterrows():
all_skills = []
# Itera sobre as colunas de habildiades
for i in range(20):
skill = row[f"skills/{i}"]
if not pd.isna(skill) and isinstance(skill, str):
skill = skill.lower() # Tudo em letra minúscula
skill = re.sub(r'[^a-zA-Z0-9\s]', '', skill) # Tira acentos e caracteres especiais
skill_tokens = word_tokenize(skill)
skill_stemmed = [stemmer.stem(token) for token in skill_tokens]
all_skills.extend(skill_stemmed)
bag_of_skills.append(all_skills)
df_bag_of_skills = pd.DataFrame({'merged_skills': bag_of_skills}) # Junta a informação de todas as colunas em uma única lista em uma coluna
return df_bag_of_skillsPor fim, a comparação dos dois data frames gerados com a frase de input será dividida em 4 etapas: Criação de vetores vazios, preenchimento dos vetores com informações analíticas das frequências das palavras, equalizar em tamanho os vetores comparados, pois a caso o vetor da frase de input não tenha o mesmo tamanho do vetor da descrição do candidato, por exemplo, algum deles terá de ser completados com zeros, e por fim o cálculo da similaridade.
Criando os vetores vazios
def vetores_desc():
lista_vetor_desc = []
for index, row in bag_descricao.iterrows():
descricao = len(row['Tokens']) * [0]
lista_vetor_desc.append(descricao)
return lista_vetor_desc
def vetores_skill():
lista_vetor_skills = []
for index, row in bag_skills.iterrows():
skills = len(row['merged_skills']) * [0]
lista_vetor_skills.append(skills)
return lista_vetor_skillsPara o preenchimento dos vetores, ele contará cada palavra tokenizada o contará a frequência dessa palavra que será contabilizada no vetor com base no índice, assim garantindo que serão comparados tokens iguais.
def preench_vetor():
vetor1 = vetores_desc()
vetor2 = vetores_skill()
frase_consulta = lista_frase_stem
for index, row in bag_descricao.iterrows():
for palavra in frase_consulta:
if palavra in row['Tokens']:
index_palavra1 = row['Tokens'].index(palavra)
for i in range(0, len(vetor1)):
if index_palavra1 < len(vetor1[i]):
vetor1[i][index_palavra1] += 1
for index, row in bag_skills.iterrows():
for palavra in frase_consulta:
if palavra in row['merged_skills']:
index_palavra2 = row['merged_skills'].index(palavra)
for t in range(0, len(vetor2)):
if index_palavra2 < len(vetor2[t]):
vetor2[t][index_palavra2] += 1
return vetor1, vetor2Por fim, a função final calcula a similaridade dos cossenos após equalizar os vetores:
def calc_sim_coss():
vetor1, vetor2 = preench_vetor()
vet_b_d = vetor_busca_desc()
vet_b_s = vetor_busca_skill()
dist1 = []
dist2 = []
# Ajustar o tamanho dos vetores em vet_b_d e vetor1
for i in range(len(vet_b_d)):
max_len1 = max(len(vet_b_d[i]), len(vetor1[i]))
if len(vet_b_d[i]) < max_len1:
vet_b_d[i] += [0] * (max_len1 - len(vet_b_d[i]))
if len(vetor1[i]) < max_len1:
vetor1[i] += [0] * (max_len1 - len(vetor1[i]))
# Ajustar o tamanho dos vetores em vet_b_s e vetor2
for i in range(len(vet_b_s)):
max_len2 = max(len(vet_b_s[i]), len(vetor2[i]))
if len(vet_b_s[i]) < max_len2:
vet_b_s[i] += [0] * (max_len2 - len(vet_b_s[i]))
if len(vetor2[i]) < max_len2:
vetor2[i] += [0] * (max_len2 - len(vetor2[i]))
# Calcule as distâncias de similaridade cosseno para vet_b_d e vetor1
for i in range(len(vet_b_d)):
try:
dist1.append(1 - distance.cosine(vet_b_d[i], vetor1[i]))
except Exception:
pass
# Calcule as distâncias de similaridade cosseno para vet_b_s e vetor2
for i in range(len(vet_b_s)):
try:
dist2.append(1 - distance.cosine(vet_b_s[i], vetor2[i]))
except Exception:
pass
return dist1, dist2Conclusão
Por fim, o resultado são duas listas: uma contendo a similaridade da frase de input com o vetor da descrição do perfil do candidato e outra contendo a similaridade da frase de input com as habilidades. É possível ainda trazer para um dataframe final o URL do perfil para compor uma lista dos candidatos mais qualificados para a vaga representada pela sua frase de input, conforme os valores das métrica empregada.
Nota-se que essa abordagem utiliza um web scraper pronto e talvez não seja o ideal para o seu negócio ou para seu RH. Caso deseje obter opções mais personalizadas deve-se criar um plano para coleta de dados direcionados em um público ou local específico.


