
Artigo escrito com a colaboração de Valéria Nicéria da Silva
O processamento de linguagem natural (PLN) é uma área dentro da Inteligência Artificial que busca fazer com que os computadores entendam e simulem uma linguagem humana. É usado no Google Translate, em sistemas de reconhecimentos e sintetização de falas, respostas automáticas e análises de sentimento. Mas como será que o PLN funciona na prática?
No artigo de hoje vamos falar um pouco mais sobre esse processamento e explicar como fazer uma análise de sentimentos usando o R para estudar uma pequena amostra de tweets.
Mineração de texto
Todo o processamento de linguagem natural só é possível por causa da mineração e extração de significado dos conteúdos postados na internet, o chamado big data. Quando falamos de conteúdo queremos dizer de artigos – em blogs como este –, notícias, comentários nas redes sociais e tudo o que é colocado na internet em forma de texto.
Esses conteúdos são considerados dados não estruturados. A mineração de texto é importante para transformá-los em dados estruturados: organizados em tabelas e devidamente identificados para que possam ser analisados. Só assim é possível extrair informações relevantes deles. Esses dados podem ser usados, por exemplo, para realizar diferentes análises de mercado, produzir matérias jornalísticas ou pesquisas científicas.
Resumindo, a mineração de texto tem como objetivo encontrar termos relevantes e estabelecer relacionamento entre eles de acordo com a sua frequência para extrair informações de grandes volumes de textos.
Workflow
Para realizar essa tarefa precisamos estabelecer um fluxo que deve ser seguido para orientar o nosso trabalho e evitar a coleta de dados que não são úteis ou análises que não são compatíveis com os dados disponíveis. O processo de obtenção dessas informações segue a seguinte lógica:
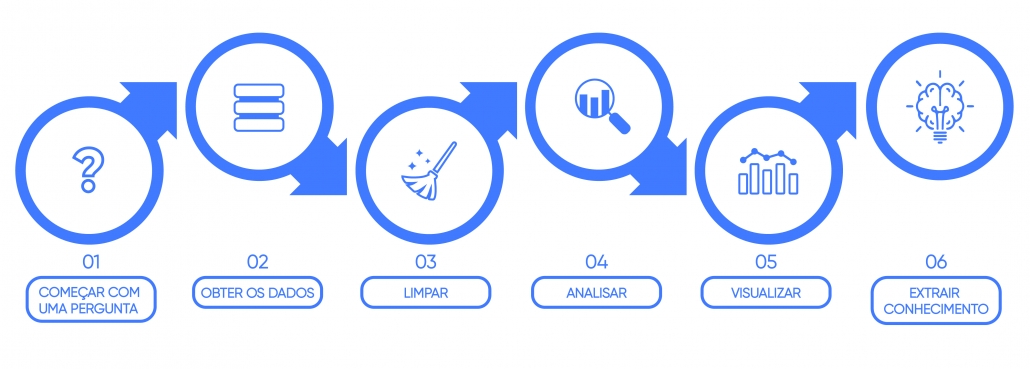
Começar com uma pergunta: primeiro devemos ter um problema que queremos resolver, ou uma pergunta que desejamos responder, como “o que as pessoas estão falando sobre data science?”
Obter os dados: com essa pergunta em mente, precisamos usar os dados para respondê-la. Para isso, utilizaremos como fonte de dados o que as pessoas estão postando no Twitter.
Limpar: depois de coletar os dados, passamos para a limpeza deles, removendo caracteres especiais – como acentos e pontuações – e transformando todas as letras em minúsculo. Depois disso retiramos também todas as stopwords, que são palavras irrelevantes para a pergunta que queremos responder.
Analisar: com tudo isso pronto, iremos realizar uma das partes mais divertidas que é analisar os dados. Aqui podemos aplicar diversas técnicas e verificar se conseguimos responder a pergunta que nos motivou a analisar esses dados.
Visualizar: nessa etapa, queremos ver o resultado da nossa análise e assim gerar diversas opções de gráficos como nuvem de palavras, gráfico de barras, dendogramas, entre outros.
Extrair conhecimento: a última parte do processo, e o objetivo do trabalho, é gerar conhecimento a partir das análises realizadas, agregando ainda mais ao nosso entendimento prévio sobre o assunto.
Código de exemplo
Para entender mais sobre o assunto criaremos um projeto básico de text mining. Para isso, utilizaremos a linguagem de programação R e os seguintes pacotes:
- ‘rtweet’ permite que você, caso tenha uma conta, se conecte ao Twitter e realize buscas de até 18 mil tweets.
- ‘tm’ o pacote tm, de “Text Mining”, é utilizado para trabalhar com textos.
- ‘wordcloud2’ permite visualizar as palavras mais usadas em tamanhos diferentes de acordo com a frequência em que cada uma delas aparece.
- ‘tydeverse’ possui uma coleção de pacotes inclusos que ajudam na manipulação dos dados.
Primeiro, vamos instalar os pacotes que serão necessários durante o projeto:
# Instalando os pacotes
install.packages("rtweet")
install.packages("tm")
install.packages("wordcloud")
install.packages("tidyverse")
E, com os pacotes instalados, devemos carregá-los para utilizar suas funções.
# Carregando os pacotes library(tm) library(rtweet) library(wordcloud) library(tidyverse)
Precisaremos de dados e vamos coletar esses dados utilizando a API do Twitter e a função de busca ‘search_tweets()’. Informamos a # que iremos buscar, o número de tweets (que não pode ultrapassar 18 mil), diremos também que não queremos os retweets e que o idioma dos tweets deverá ser o inglês.
# Buscando os tweets com a #datascience datascience_tweet <- search_tweets( "#datascience", n = 18000, include_rts = FALSE, lang = "en" )
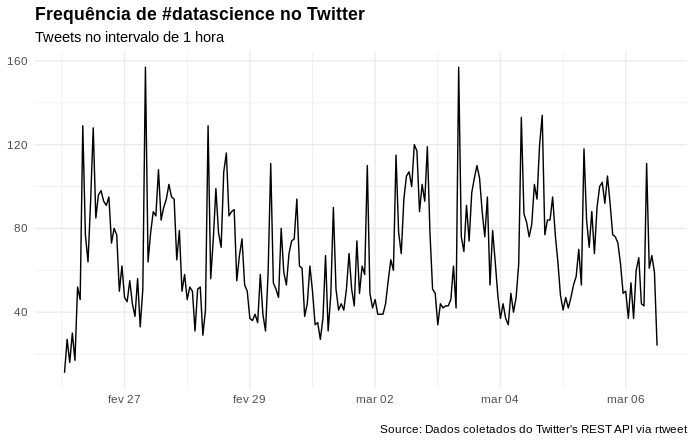
Visualizando a frequência de tweets que utilizam a #datascience no intervalo de 1 hora:
# Gerando um gráfico com a frequencia dos tweets no intervalo de 1 hora
datascience_tweet %>%
ts_plot("1 hours") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frequência de #datascience no Twitter",
subtitle = "Tweets no intervalo de 1 hora",
caption = "\nSource: Dados coletados do Twitter's REST API via rtweet"
)
Para começar a mineração de texto vamos atribuir uma variável para a coluna text.
# Atribuindo os textos a uma variável datascience_texto <- datascience_tweet$text
Em seguida limpamos o corpus que é o total de textos colhidos. Para isso utilizamos a função tm_map, onde removeremos os caracteres especiais, transformaremos todas as letras para minúsculas, removeremos as pontuações e as stopwords em inglês.
# Transformando os textos em um corpus
datascience_corpus <- VCorpus(VectorSource(datascience_texto))
# Realizando a limpeza do corpus
datascience_corpus <-
tm_map(
datascience_corpus,
content_transformer(
function(x) iconv(x, from = 'UTF-8', to = 'ASCII//TRANSLIT')
)
) %>%
tm_map(content_transformer(tolower)) %>%
tm_map(removePunctuation) %>%
tm_map(removeWords, stopwords("english"))
Após realizar a limpeza dos textos, podemos visualizar o resultado da pesquisa em uma nuvem de palavras. Usamos a função brewer.pal para gerar as cores em hexadecimal e assim colorirmos a nuvem.
# Lista de cores em hexadecimal paleta <- brewer.pal(8, "Dark2") # Criando uma nuvem de palavras, com no máximo 100 palavras # onde tenha se repetido ao menos 2 vezes. wordcloud( datascience_corpus, min.freq = 2, max.words = 100, colors = paleta )

Em seguida criamos uma matriz de documentos-termos (DocumentTermMatrix). Removemos os termos menos frequentes da matriz e somamos os termos restantes para assim verificar quais aparecem mais vezes.
# Criando uma matriz de termos datascience_document <- DocumentTermMatrix(datascience_corpus) # Removendo os termos menos frequentes datascience_doc <- removeSparseTerms(datascience_document, 0.98) # Gerando uma matrix ordenada, com o termos mais frequentes datascience_freq <- datascience_doc %>% as.matrix() %>% colSums() %>% sort(decreasing = T)
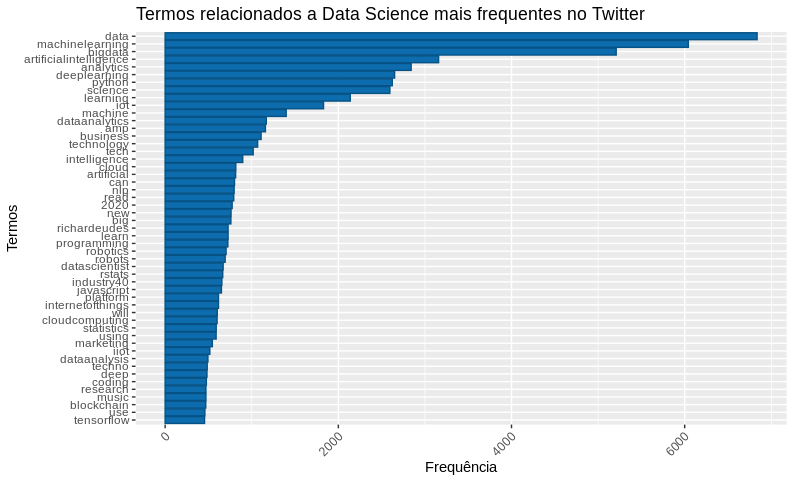
Geramos um dataframe com os termos mais frequentes e visualizamos em um gráfico.
# Criando um dataframe com as palavras mais frequentes
df_datascience <- data.frame(
word = names(datascience_freq),
freq = datascience_freq
)
# Gerando um gráfico da frequência
df_datascience %>%
filter(!word %in% c("datascience", "via")) %>%
subset(freq > 450) %>%
ggplot(aes(x = reorder(word, freq),
y = freq)) +
geom_bar(stat = "identity", fill='#0c6cad', color="#075284") +
theme(axis.text.x = element_text(angle = 45, hjus = 1)) +
ggtitle("Termos relacionados a Data Science mais frequentes no Twitter") +
labs(y = "Frequência", x = "Termos") +
coord_flip()
Podemos também visualizar o resultado em uma nuvem de palavras utilizando o pacote wordcloud2 para gerar a nuvem.
# Carregando o pacote 'devtools'
library(devtools)
# Instalando o pacote 'wordcloud2'
devtools::install_github("lchiffon/wordcloud2")
Passamos o dataframe com os termos mais frequentes para a função wordcloud2 e teremos como resultado o seguinte gráfico.
# Carregando o pacote 'wordcloud2' library(wordcloud2) wordcloud2(data = df_datascience)

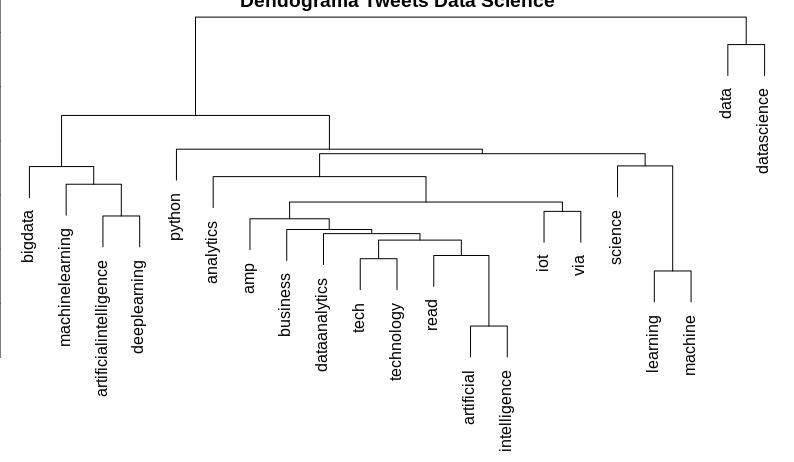
Podemos visualizar como os nossos termos estão agrupados. Para isso produziremos um dendrograma de agrupamento hierárquico, ou diagrama de árvore.
# Removendo os termos menos frequentes datascience_doc1 <- removeSparseTerms(datascience_document, 0.95) # Clustering 1 = Dendograma distancia <- dist(t(datascience_doc1), method = "euclidian") dendograma <- hclust(d = distancia, method = "complete") plot(dendograma, habg = -1, main = "Dendograma Tweets Data Science", xlab = "Distância", ylab = "Altura")
Esse é um exemplo de como podemos utilizar a mineração de texto para extrair informações relevantes de uma grande quantidade de conteúdo disponível na internet. Essa é a primeira parte de como fazer um processamento de linguagem natural.
Agora vamos pegar outro exemplo de como isso pode ser feito e quais os resultados que podem ser extraídos de uma análise se sentimos.
Para esse exemplo tentaremos responder a seguinte pergunta “qual é o sentimento das pessoas em relação à economia?”. Depois de definir a pergunta, precisamos de uma fonte de dados e para isso utilizaremos os comentários do Twitter. O projeto de exemplificação será construído utilizando a linguagem R e será necessário ter os seguintes pacotes instalados em seu computador:
- ‘tydeverse’ É um pacote, que possui uma coleção de pacotes inclusos, para ajudar na manipulação dos dados;
- ‘rtweet’ É um pacote, que permitirá que você se conecte ao Twitter, caso você tenha uma conta, onde você poderá realizar buscas, com no máximo 18 mil tweets;
- ‘tm’ O pacote tm de “Text Mining” é um pacote utilizado para trabalharmos com textos;
- ‘wordcloud’ É um pacote que nos permite visualizar de forma rápida, as palavras, utilizando como critério de tamanho, a frequência;
- ‘syuzhet’ É um pacote, que utilizaremos para classificar os sentimentos.
# Instalando os pacotes
install.packages("tydeverse")
install.packages("rtweet")
install.packages("tm")
install.packages("wordcloud")
install.packages("syuzhet")
Vamos carregar os pacotes.
# Carregando os pacotes library(tydeverse) library(rtweet) library(tm) library(wordcloud) library(syuzhet)
Agora vamos buscar os textos utilizando a função search_tweets do pacote rtweet. Utilizaremos como amostra 2 mil tweets e esses tweets estarão em inglês.
# Buscando tweets relacionados a economia economia_tweets <- search_tweets( "#economy", n = 2000, include_rts = FALSE, lang = "en" )
Para fazer o pré-processamento do texto e para simplificar nosso trabalho, vamos separar a coluna ‘text’ em uma variável.
# Separando o texto economia_text <- economia_tweets$text
Para fazer a limpeza dos textos podemos utilizar as funções do pacote tm, ou podemos criar as nossas próprias funções, como no exemplo abaixo:
# Função para limpeza dos textos
limpar_texto <- function(texto) {
# Convertendo o texto para minúsculo
texto <- tolower(texto)
# Removendo o usuário adicionado no comentário
texto <- gsub("@\\w+", "", texto)
# Removendo as pontuações
texto <- gsub("[[:punct:]]", "", texto)
# Removendo links
texto <- gsub("http\\w+", "", texto)
# Removendo tabs
texto <- gsub("[ |\t]{2,}", "", texto)
# Removendo espaços no início do texto
texto <- gsub("^ ", "", texto)
# Removendo espaços no final do texto
texto <- gsub(" $", "", texto)
return(texto)
}
Utilizando a função criada para limpar o texto temos:
# Limpando os textos economia_text <- limpar_texto(economia_text)
Transformamos o texto limpo em um corpus e depois usamos o pacote tm para remover as stopwords.
# Convertendo os textos em corpus
economia_corpus <- VCorpus(VectorSource(economia_text))
# Removendo stopwords
economia_corpus % tm_map(removeWords, stopwords("english"))
Após a limpeza, podemos visualizar os textos em uma nuvem de palavras, para descobrir os termos mais frequentes no conjunto de dados.
# Lista de cores em hexadecimal paleta <- brewer.pal(8, "Dark2") wordcloud( economia_corpus, min.freq = 15, max.words = 250, random.order = F, colors = paleta )
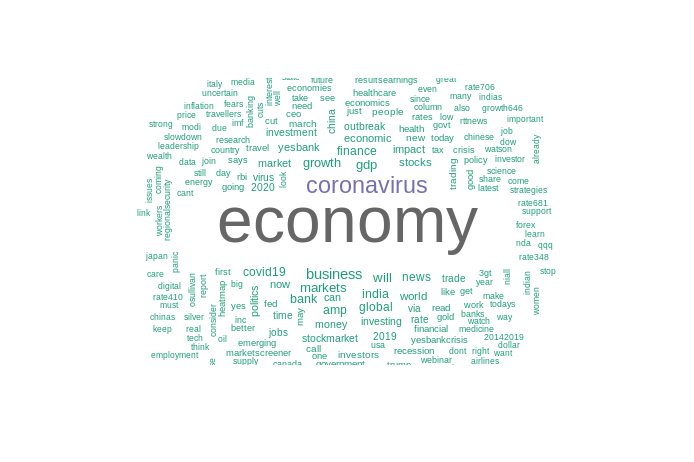
Agora transformaremos o nosso corpus em uma matriz de documentos-termos para criarmos um gráfico de barras com os termos e sua frequência.
# Lista de cores em hexadecimal
# Transformando o corpus em matriz de documentos-termos
economia_doc <- DocumentTermMatrix(economia_corpus)
# Removendo os termos menos frequentes
economia_doc1 <- removeSparseTerms(economia_doc, 0.97)
# Gerando uma matrix ordenada, com o termos mais frequentes
economia_freq <-
economia_doc1 %>%
as.matrix() %>%
colSums() %>%
sort(decreasing = T)
# Criando um dataframe com as palavras mais frequentes
df_economia_freq <- data.frame(
word = names(economia_freq),
freq = economia_freq
)
# Gerando um gráfico da frequência
df_economia_freq %>%
filter(!word %in% c("economy")) %>%
subset(freq > 50) %>%
ggplot(aes(x = reorder(word, freq),
y = freq)) +
geom_bar(stat = "identity", fill='#0c6cad', color="#075284") +
theme(axis.text.x = element_text(angle = 45, hjus = 1)) +
ggtitle("Termos relacionados a Economia mais frequentes no Twitter") +
labs(y = "Frequência", x = "Termos") +
coord_flip()
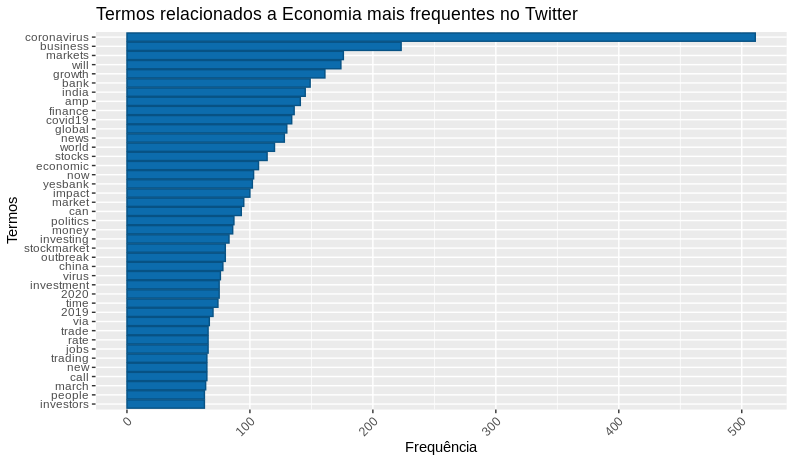
Criando um dendrograma (diagrama de árvore) onde será possível visualizar o agrupamento dos nossos termos.
# Dendrograma -> Visualizando os grupos
distancia <- dist(t(economia_doc1), method = "euclidian")
dendrograma <- hclust(d = distancia, method = "complete")
plot(dendrograma, habg = -1, main = "Dendrograma Tweets Economia",
xlab = "Distância",
ylab = "Altura")
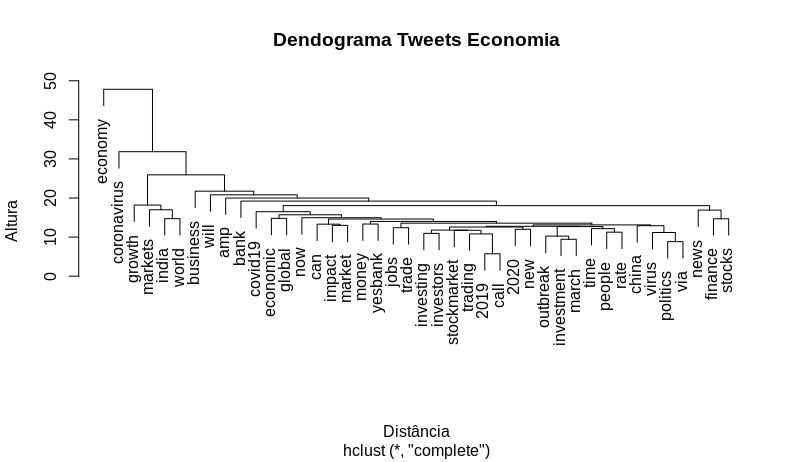
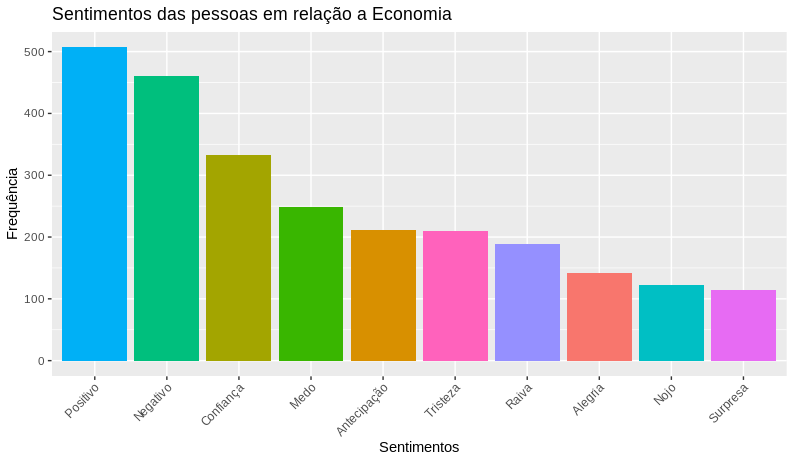
E por último realizaremos a análise de sentimentos dos tweets. Para isso utilizaremos a função get_nrc_sentiment do pacote syuzhet e passaremos como parâmetro os termos da matriz de documentos-termos. Após obtermos as emoções dos termos, faremos o cálculo da frequência dos sentimentos que utilizaram a #economy.
# Obtendo os emoções economia_sentimento <- get_nrc_sentiment( economia_doc$dimnames$Terms, language = "english" ) # Calculando a frequência dos sentimentos economia_sentimento_freq % colSums() %>% sort(decreasing = T)
Com a frequência calculada, vamos traduzir os sentimentos do inglês para o português e transformar o resultado em um dataframe para depois gerar o gráfico e visualizar os resultados.
# Criando um dataframe com os sentimentos traduzidos, que será utilizado como de-para.
sentimetos_traducao <-
data.frame(
sentiment = c(
"positive",
"negative",
"trust",
"anticipation",
"fear",
"joy",
"sadness",
"surprise",
"anger",
"disgust"
),
sentimentos = c(
"Positivo",
"Negativo",
"Confiança",
"Antecipação",
"Medo",
"Alegria",
"Tristeza",
"Surpresa",
"Raiva",
"Nojo"
)
)
# Tranformando os resultados da frequência em um dataframe
# e juntando ao dataframe de tradução
df_sentimento <-
data.frame(
sentiment = names(economia_sentimento_freq),
freq = economia_sentimento_freq
) %>%
left_join(sentimetos_traducao, by = "sentiment") %>%
dplyr::select(-sentiment) %>%
arrange(desc(freq))
# Visualizando a frequência dos sentimentos em relação a #economy
ggplot(data = df_sentimento,
aes(x = reorder(sentimentos, -freq), y = freq)) +
geom_bar(aes(fill=sentimentos), stat = "identity") +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjus = 1)) +
xlab("Sentimentos") +
ylab("Frequência") +
ggtitle(titulo)



1 comentário em “Um exemplo prático de PLN (processamento de linguagem natural)”
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.