

Artigo escrito com a colaboração de Maísa Aparecida de Andrade
O pacote Mice no software R é um importante recurso quando temos uma base de dados com poucos elementos faltantes. Às vezes alguns dados estão errados, comprometidos ou simplesmente não existem. Desconsiderar esses dados pode ser um problema para a análise e imputá-los por meio da média também não é o ideal porque nem sempre a média é o melhor preditor para os dados.
Este pacote ajuda a imputar valores plausíveis de dados, obtidos de uma distribuição projetada especificamente para cada ponto de dados ausente. O método de imputação leva um conjunto de preditores e retorna uma única imputação para cada entrada em falta na coluna incompleta. De modo que para imputar cada dado ausente, consulta-se todos os outros dados da planilha.
Neste pacote, para cada uma das variáveis pode ser atribuído um modelo de imputação diferente. Portanto, um conjunto de dados pode ter variáveis tanto contínuas como categóricas.
Alguns pontos importantes
- Antes de realizar a imputação, devemos analisar o banco de dados, a fim de descobrir se os dados ausentes são aleatórios ou se é alguma falha da pesquisa, pois o R admite que os dados ausentes são aleatórios.
- Os melhores resultados do pacote Mice, são quando o banco de dados possui até 5% de dados ausentes, porém ele realiza a imputação com qualquer porcentagem de missing.
- A imputação considera a classe da variável. Se a classe for inteiro, ele só imputará dados inteiros.
- Para imputar variáveis categóricas o ideal é mudar a classe para fator e depois para inteiro.
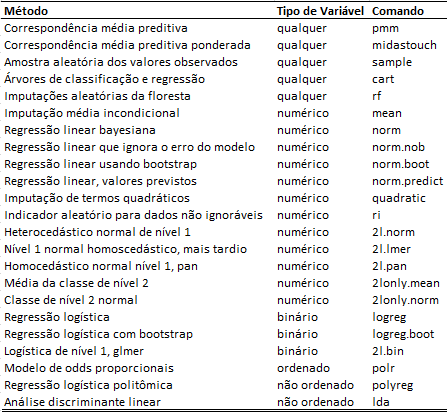
Métodos de imputação
Para demonstrar as funcionalidades do pacote Mice, realizamos uma imputação em um banco de dados sobre os municípios brasileiros referentes ao ano de 2010. Este banco de dados já possuía alguns dados ausentes, mas produzi 10% de missing para demonstrar como a imputação acontece.
Pacotes Utilizados
library(tidyverse)
library(missForest) #gerar dados ausentes
library(finalfit) #vizualização de dados ausentes
library(mice) #pacote para imputação de dadosLendo bancos de dados
dados = read.csv2("C:/Users/DataTalker/Desktop/dados_completo.csv")
missing = read.csv2("C:/Users/DataTalker/Desktop/missing.csv")Analisando os dados
glimpse(missing) Observations: 5,254
Variables: 17
$ UF <fct> RO, RO, RO, RO, RO, RO, RO, RO, RO,...
$ Município <fct> Ariquemes, Cabixi, Cacoal, Cerejeir...
$ Região <fct> Região Norte, Região Norte, Região ...
$ Capital <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,...
$ População.2010 <int> 90353, 6313, 78574, 17029, NA, 1367...
$ Porte <fct> Médio, NA, Médio, NA, Pequeno I, Pe...
$ Agropecuaria <int> 73712, 24301, 95259, 28976, 51206, ...
$ Indústria <int> 287139, 3253, 182052, NA, NA, 7732,...
$ Serviços <int> 494946, 12677, 465447, 80725, 15591...
$ Administração_eoutros <int> 343868, NA, 298454, 63018, NA, 5107...
$ Valor._bruto_tota <int> 1199664, 65401, 1041212, 192454, 10...
$ Impostos_eoutros <int> 165030, 4210, 145282, 29567, 6013, ...
$ PIB <int> 1364694, 69611, 1186494, 222021, 11...
$ PIB_percapita <int> 15104, 11034, 15095, 13037, 13039, ...
$ Empresas_atraídas <int> 109, NA, 101, 26, 11, 4, 59, 41, 57...
$ Classificação_gestaopubli <int> NA, NA, 9, 9, NA, 9, 9, 9, 6, 9, NA...
$ Classificação_gestaoterrit <int> 7, NA, 7, 9, NA, 9, 8, 8, 5, 8, NA,...Analisando dados faltantes
Quantidade total de dados ausentes. Corresponde a 12,6% do banco
sum(is.na(missing)) #12,67% de dados ausentes[1] 11310Imputação de dados usando Mice
Primeiro criamos uma imputação de dados com iteração 0, apenas para definir os parâmetros, que são:
- maxit = o número de iterações. O padrão é 5.
- method = o método de imputação. O padrão é “pmm”.
- predictorMatrix = uma matriz numérica de predição. O padrão é uma matriz quadrada compostas por 1, e 0 na diagonal.
- m = número de imputações a serem feitas. O padrão é 5.
imp= missing
init = mice(data=imp, maxit = 0)
meth = init$method
predM = init$predictorMatrixDessa forma temos uma imputação “vazia” e fica mais fácil definir os parâmetros para a nossa imputação. Antes disso, devemos conferir os dados e ver se as classes estão corretas, pois caso não esteja tem uma grande chance do R travar.
glimpse(imp)Observations: 5,254
Variables: 17
$ UF <fct> RO, RO, RO, RO, RO, RO, RO, RO, RO,...
$ Município <fct> Ariquemes, Cabixi, Cacoal, Cerejeir...
$ Região <fct> Região Norte, Região Norte, Região ...
$ Capital <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,...
$ População.2010 <int> 90353, 6313, 78574, 17029, NA, 1367...
$ Porte <fct> Médio, NA, Médio, NA, Pequeno I, Pe...
$ Agropecuaria <int> 73712, 24301, 95259, 28976, 51206, ...
$ Indústria <int> 287139, 3253, 182052, NA, NA, 7732,...
$ Serviços <int> 494946, 12677, 465447, 80725, 15591...
$ Administração_eoutros <int> 343868, NA, 298454, 63018, NA, 5107...
$ Valor._bruto_tota <int> 1199664, 65401, 1041212, 192454, 10...
$ Impostos_eoutros <int> 165030, 4210, 145282, 29567, 6013, ...
$ PIB <int> 1364694, 69611, 1186494, 222021, 11...
$ PIB_percapita <int> 15104, 11034, 15095, 13037, 13039, ...
$ Empresas_atraídas <int> 109, NA, 101, 26, 11, 4, 59, 41, 57...
$ Classificação_gestaopubli <int> NA, NA, 9, 9, NA, 9, 9, 9, 6, 9, NA...
$ Classificação_gestaoterrit <int> 7, NA, 7, 9, NA, 9, 8, 8, 5, 8, NA,...Vamos agora mudar as classes das variáveis para que tudo ocorra certo.
imp <- imp %>%
mutate(UF = as.character(imp$UF),
Município = as.character(imp$Município),
Região = as.character(imp$Região),
Porte = as.integer(imp$Porte),
Agropecuaria = as.numeric(imp$Agropecuaria),
Indústria = as.numeric(imp$Indústria),
Serviços = as.numeric(imp$Serviços),
Administração_eoutros = as.numeric(imp$Administração_eoutros),
Valor._bruto_tota = as.numeric(imp$Valor._bruto_tota),
Impostos_eoutros = as.numeric(imp$Impostos_eoutros),
PIB = as.numeric(imp$PIB),
PIB_percapita = as.numeric(imp$PIB_percapita))Verificando as variáveis.
glimpse(imp)Observations: 5,254
Variables: 17
$ UF <chr> "RO", "RO", "RO", "RO", "RO", "RO",...
$ Município <chr> "Ariquemes", "Cabixi", "Cacoal", "C...
$ Região <chr> "Região Norte", "Região Norte", "Re...
$ Capital <int> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,...
$ População.2010 <int> 90353, 6313, 78574, 17029, NA, 1367...
$ Porte <int> 2, NA, 2, NA, 4, 4, 2, 5, 1, 5, 5, ...
$ Agropecuaria <dbl> 73712, 24301, 95259, 28976, 51206, ...
$ Indústria <dbl> 287139, 3253, 182052, NA, NA, 7732,...
$ Serviços <dbl> 494946, 12677, 465447, 80725, 15591...
$ Administração_eoutros <dbl> 343868, NA, 298454, 63018, NA, 5107...
$ Valor._bruto_tota <dbl> 1199664, 65401, 1041212, 192454, 10...
$ Impostos_eoutros <dbl> 165030, 4210, 145282, 29567, 6013, ...
$ PIB <dbl> 1364694, 69611, 1186494, 222021, 11...
$ PIB_percapita <dbl> 15104, 11034, 15095, 13037, 13039, ...
$ Empresas_atraídas <int> 109, NA, 101, 26, 11, 4, 59, 41, 57...
$ Classificação_gestaopubli <int> NA, NA, 9, 9, NA, 9, 9, 9, 6, 9, NA...
$ Classificação_gestaoterrit <int> 7, NA, 7, 9, NA, 9, 8, 8, 5, 8, NA,...names(imp) [1] "UF" "Município"
[3] "Região" "Capital"
[5] "População.2010" "Porte"
[7] "Agropecuaria" "Indústria"
[9] "Serviços" "Administração_eoutros"
[11] "Valor._bruto_tota" "Impostos_eoutros"
[13] "PIB" "PIB_percapita"
[15] "Empresas_atraídas" "Classificação_gestaopubli"
[17] "Classificação_gestaoterrit"Agora que as variáveis estão da maneira correta, vamos selecionar os métodos de imputação. O método padrão “pmm” exige que a matriz de dados selecionados seja invertível. Porém, muitas vezes nos deparamos com variáveis que podem ser combinação linear de outras. Então, o ideal é trocar o método ou ver quais colunas podem ser imputadas pela correspondência média preditiva.
Neste caso usei o método de árvore de classificação. Ele é ideal para qualquer tipo de variável, tendo um bom desempenho principalmente em numéricas e categóricas com mais de 2 níveis.
meth[c(5:17)]="cart" #Árvores de classificação e regressãoDefinido o método e tendo a matriz de predição, resta apenas chamar a função. Essa parte é um pouco demorada, pois integra sobre todas as variáveis, a fim de definir a melhor imputação para cada espaço ausente.
set.seed(279)
imputed = mice(imp, method=meth %>% as.vector(), predictorMatrix=predM, m=5)
iter imp variable
1 1 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
1 2 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
1 3 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
1 4 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
1 5 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
2 1 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
2 2 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
2 3 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
2 4 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
2 5 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
3 1 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
3 2 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
3 3 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
3 4 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
3 5 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
4 1 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
4 2 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
4 3 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
4 4 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
4 5 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
5 1 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
5 2 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
5 3 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
5 4 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterrit
5 5 População.2010 Porte Agropecuaria Indústria Serviços Administração_eoutros Valor._bruto_tota Impostos_eoutros PIB PIB_percapita Empresas_atraídas Classificação_gestaopubli Classificação_gestaoterritQuando finalizado, usamos a função complete para extrair os resultados.
imp1 <- complete(imputed,1)
imp2 <- complete(imputed,2)
imp3 <- complete(imputed,3)
imp4 <- complete(imputed,4)
imp5 <- complete(imputed,5)
missing_glimpse(imp1)%>%
DT::datatable()Finalizada as imputações, basta montar o novo df sem dados ausentes.
#função de moda para variavel porte (categorica)
mode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
dados_completo = data.frame(
UF = dados$UF,
Município = dados$Município,
Região = dados$Região,
População.2010 = apply(cbind(imp1$População.2010,imp2$População.2010,imp3$População.2010,imp4$População.2010,imp5$População.2010),1,mean),
Porte = apply(cbind(imp1$Porte,imp2$Porte,imp3$Porte,imp4$Porte,imp5$Porte),1,mode),
Capital = dados$Capital,
Agropecuaria = apply(cbind(imp1$Agropecuaria,imp2$Agropecuaria,imp3$Agropecuaria, imp4$Agropecuaria,imp5$Agropecuaria),1,mean),
Indústria = apply(cbind(imp1$Indústria,imp2$Indústria,imp3$Indústria,imp4$Indústria, imp5$Indústria),1,mean),
Serviços = apply(cbind(imp1$Serviços,imp2$Serviços,imp3$Serviços,imp4$Serviços,imp5$Serviços),1,mean),
Administração_eoutros = apply(cbind(imp1$Administração_eoutros, imp2$Administração_eoutros, imp3$Administração_eoutros,imp4$Administração_eoutros,imp5$Administração_eoutros),1,mean),
Valor._bruto_tota = apply(cbind(imp1$Valor._bruto_tota ,imp2$Valor._bruto_tota ,imp3$Valor._bruto_tota ,imp4$Valor._bruto_tota ,imp5$Valor._bruto_tota ),1,mean),
Impostos_eoutros = apply(cbind(imp1$Impostos_eoutros,imp2$Impostos_eoutros,imp3$Impostos_eoutros,imp4$Impostos_eoutros,imp5$Impostos_eoutros),1,mean),
PIB = apply(cbind(imp1$PIB,imp2$PIB,imp3$PIB,imp4$PIB,imp5$PIB),1,mean),
PIB_percapita = apply(cbind(imp1$PIB_percapita,imp2$PIB_percapita,imp3$PIB_percapita, imp4$PIB_percapita,imp5$PIB_percapita),1,mean),
Empresas_atraídas = apply(cbind(imp1$Empresas_atraídas ,imp2$Empresas_atraídas, imp3$Empresas_atraídas, imp4$Empresas_atraídas ,imp5$Empresas_atraídas ),1,mode),
Classificação_gestaopubli = apply(cbind(imp1$Classificação_gestaopubli, imp2$Classificação_gestaopubli, imp3$Classificação_gestaopubli, imp4$Classificação_gestaopubli, imp5$Classificação_gestaopubli),1,mode),
Classificação_gestaoterrit = apply(cbind(imp1$Classificação_gestaoterrit, imp2$Classificação_gestaoterrit, imp3$Classificação_gestaoterrit, imp4$Classificação_gestaoterrit, imp5$Classificação_gestaoterrit),1,mode))
dados_completo <- dados_completo %>%
mutate(Porte = case_when(Porte==1~"Grande",
Porte==2~"Médio",
Porte==3~"Metrópole",
Porte==4~"Pequeno I",
Porte==5~"Pequeno II"))
dados_completo <- dados_completo %>%
mutate(Capital = case_when(Capital==0~"Não é Capital",
Capital==1~"Capital"))Qualidade da imputação
Para verificar a qualidade das imputações usei este gráfico de densidade, onde é possível comparar a densidade dos dados antes e depois da imputação.
grafico_imput = function(real,imputado,x)
{
data.frame("Antes de imputar" = real,
"Depois de imputar" = imputado) %>%
pivot_longer(everything()) %>%
na.omit() %>%
ggplot(mapping = aes(value,col= name))+
geom_density()+
theme_minimal()+
xlab(x)+
ylab("Densidade")+
theme(panel.border = element_rect(colour = "black", fill = NA, size = 0.2))+
scale_color_discrete(labels = c("Antes de imputar","Depois de imputar"))+
guides(color=guide_legend(title=""))
} Gráficos
grafico_imput(missing$População.2010,dados_completo$População.2010,"População.2010")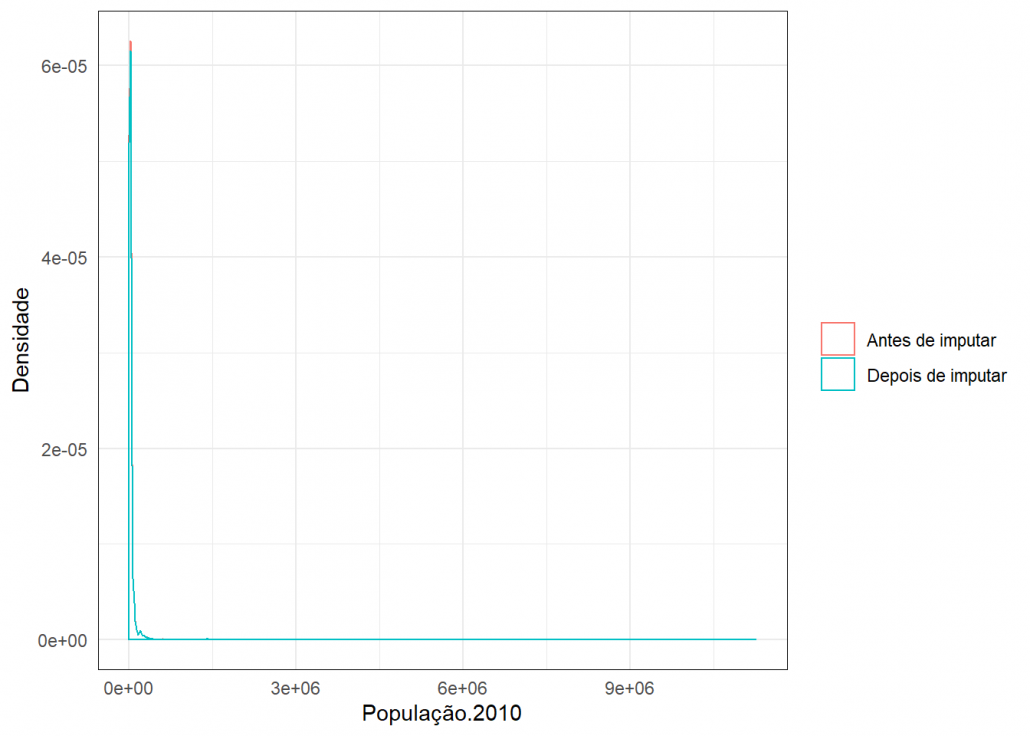
grafico_imput(missing$Agropecuaria,dados_completo$Agropecuaria,"Agropecuaria")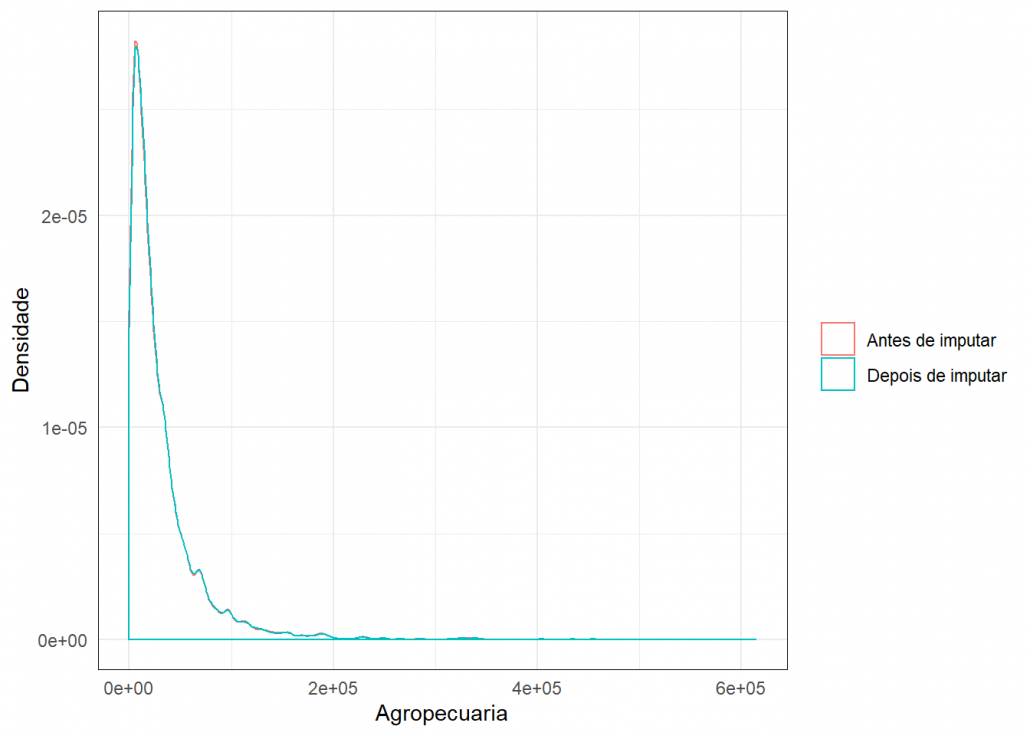
grafico_imput(missing$Indústria,dados_completo$Indústria,"Indústria")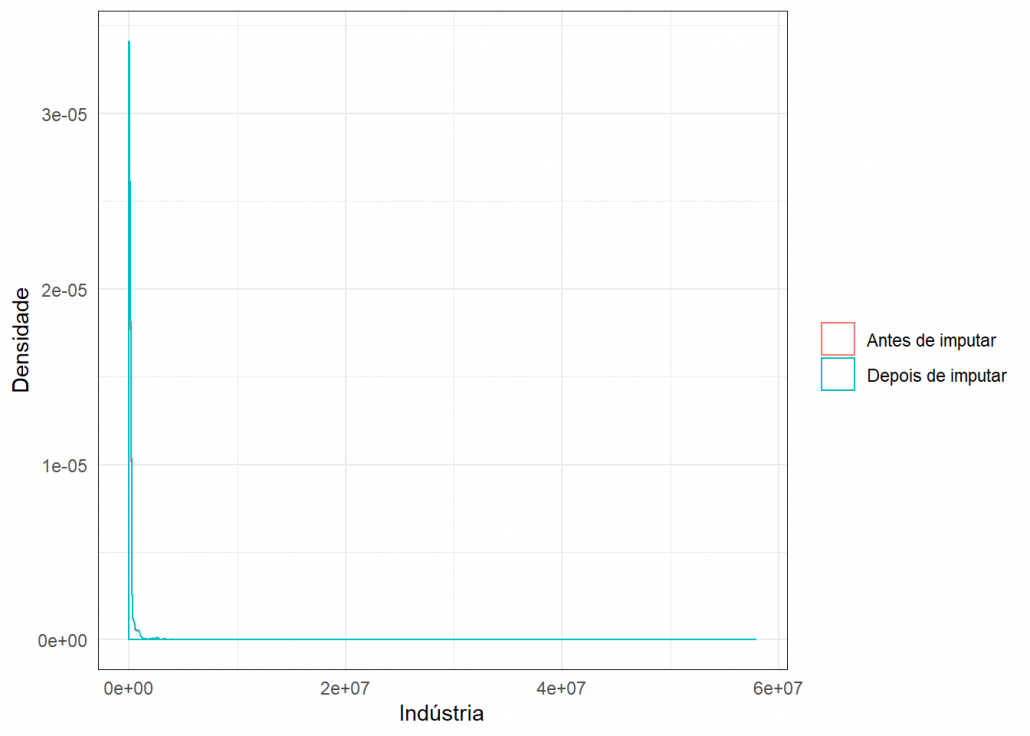
grafico_imput(missing$Serviços,dados_completo$Serviços,"Serviços")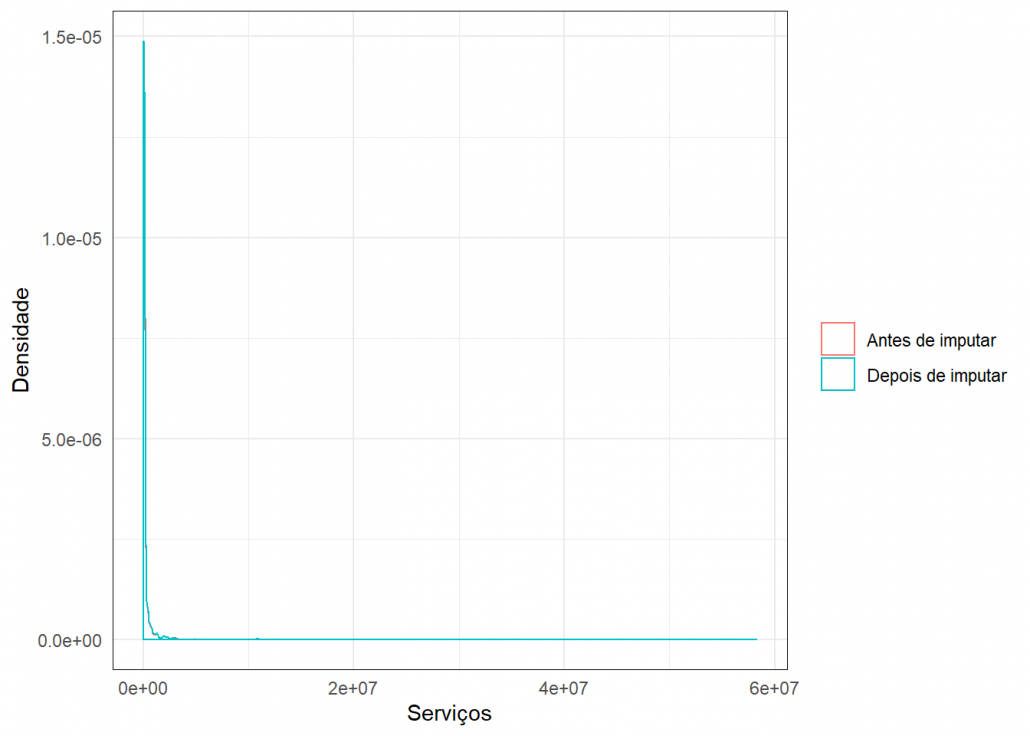
grafico_imput(missing$Administração_eoutros,dados_completo$Administração_eoutros,"Administração e outros")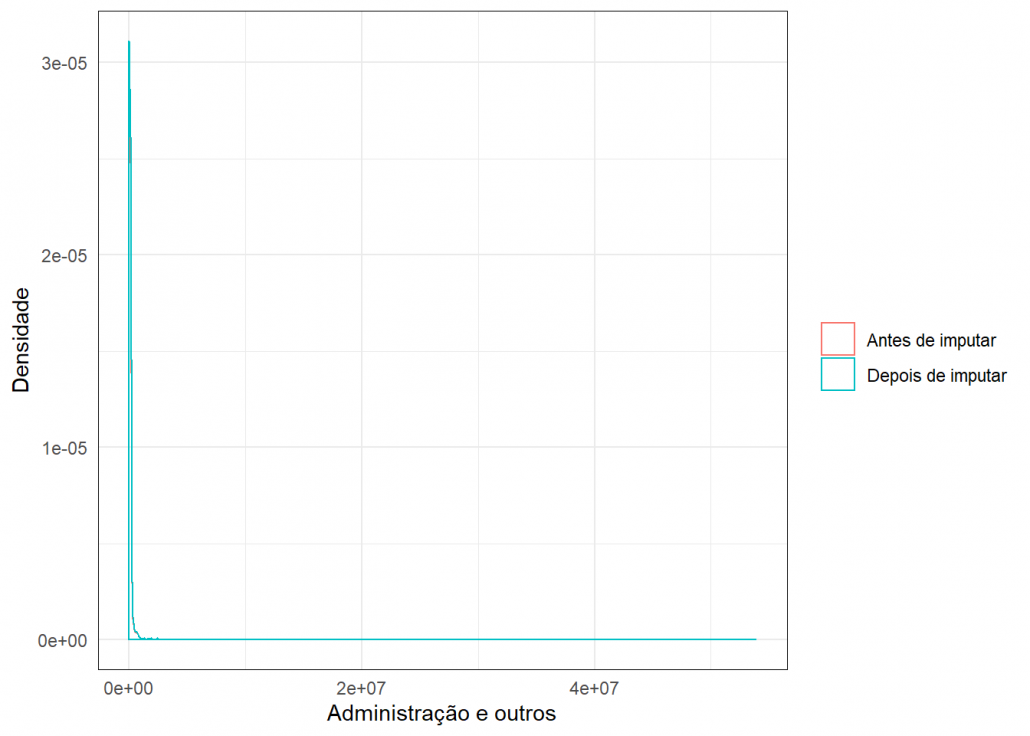
grafico_imput(missing$Valor._bruto_tota,dados_completo$Valor._bruto_tota,"Valor bruto total")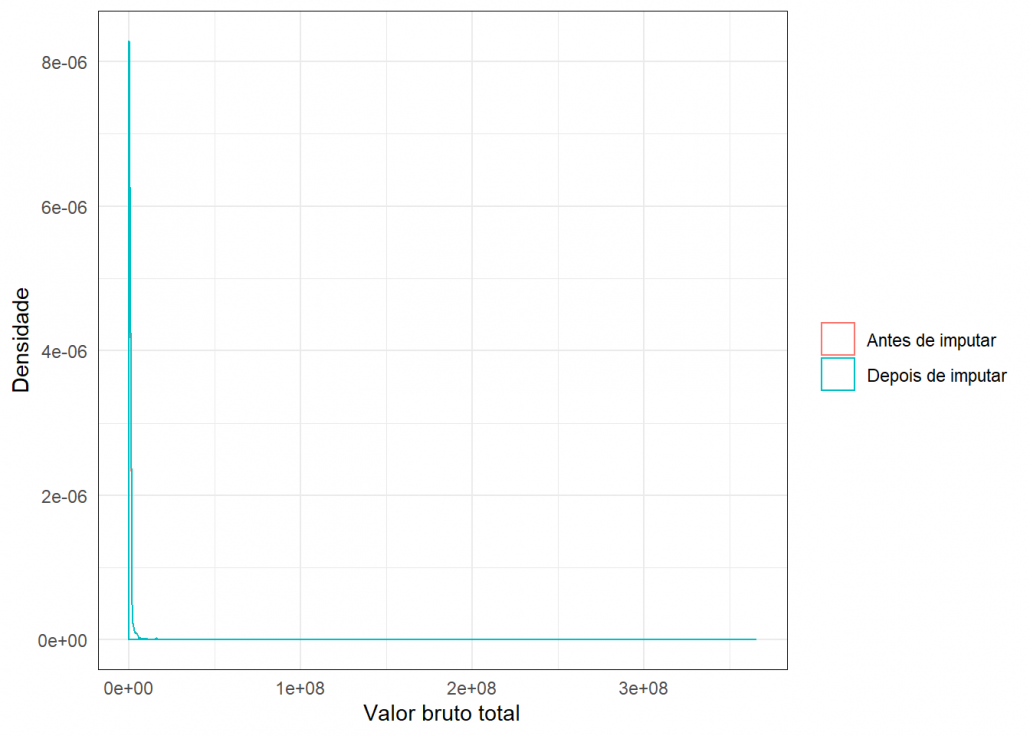
grafico_imput(missing$PIB,dados_completo$PIB,"PIB")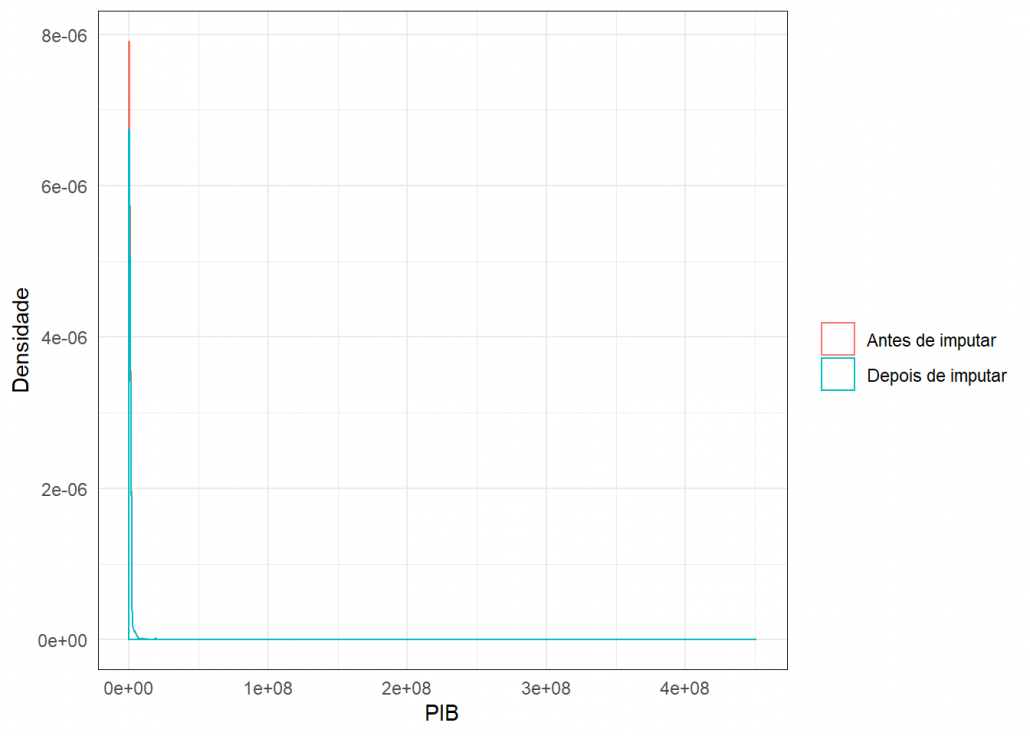
grafico_imput(missing$PIB_percapita,dados_completo$PIB_percapita,"PIB_percapita")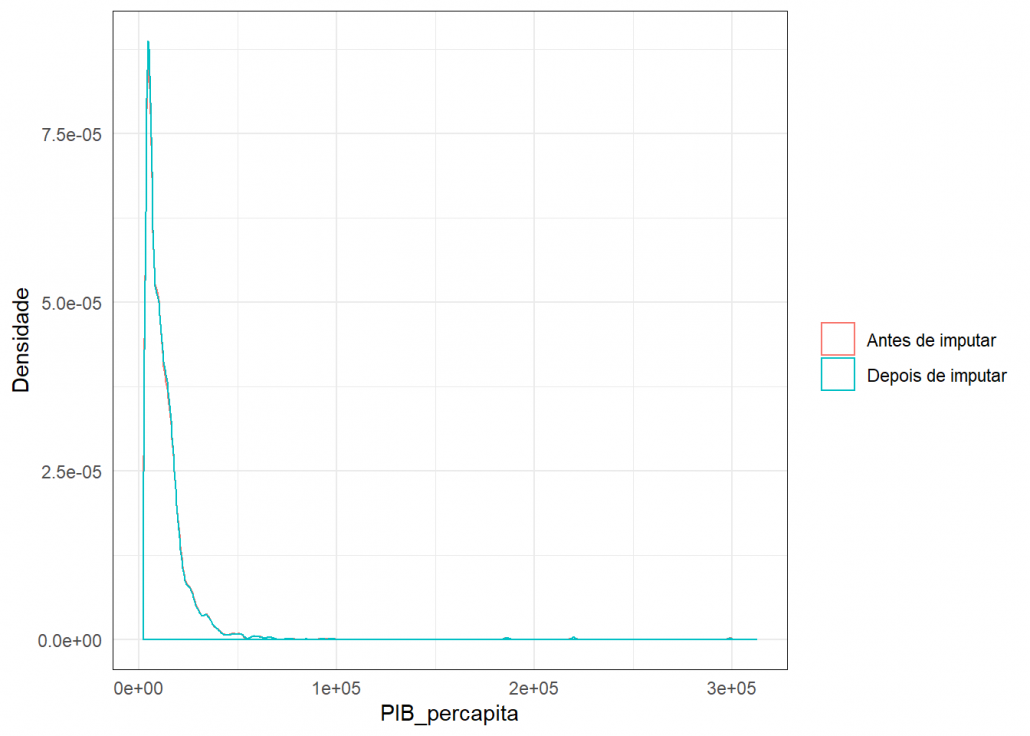
grafico_imput(missing$Empresas_atraídas,dados_completo$Empresas_atraídas,"Empresas_atraídas")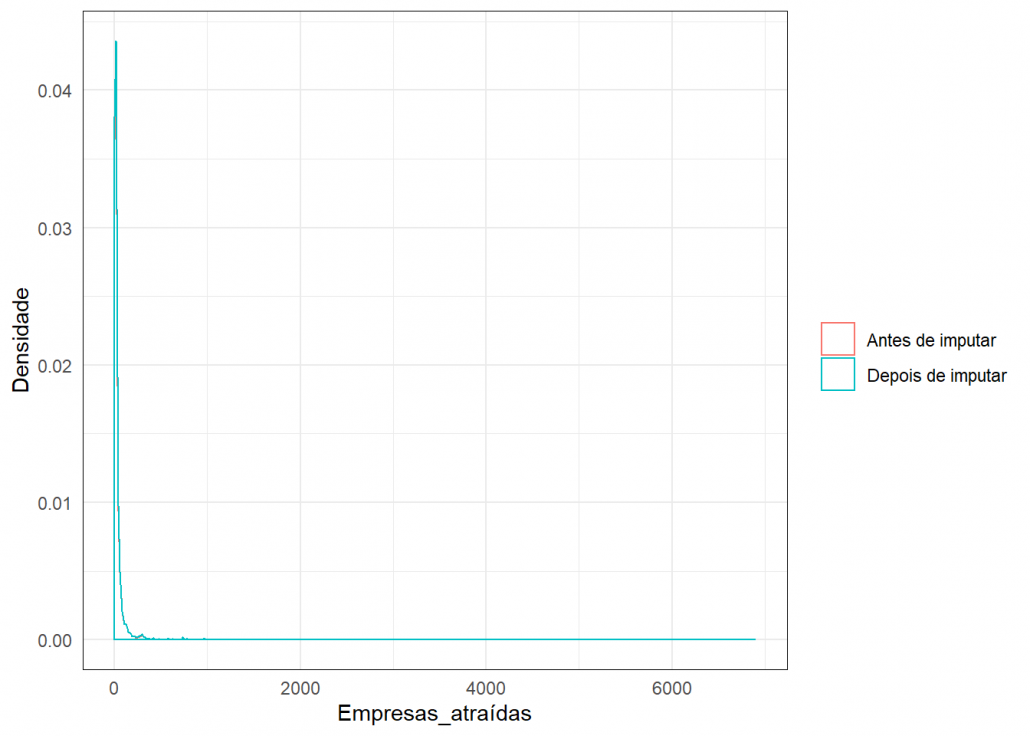
grafico_imput(missing$Classificação_gestaopubli,dados_completo$Classificação_gestaopubli,"Classificação_gestaopubli")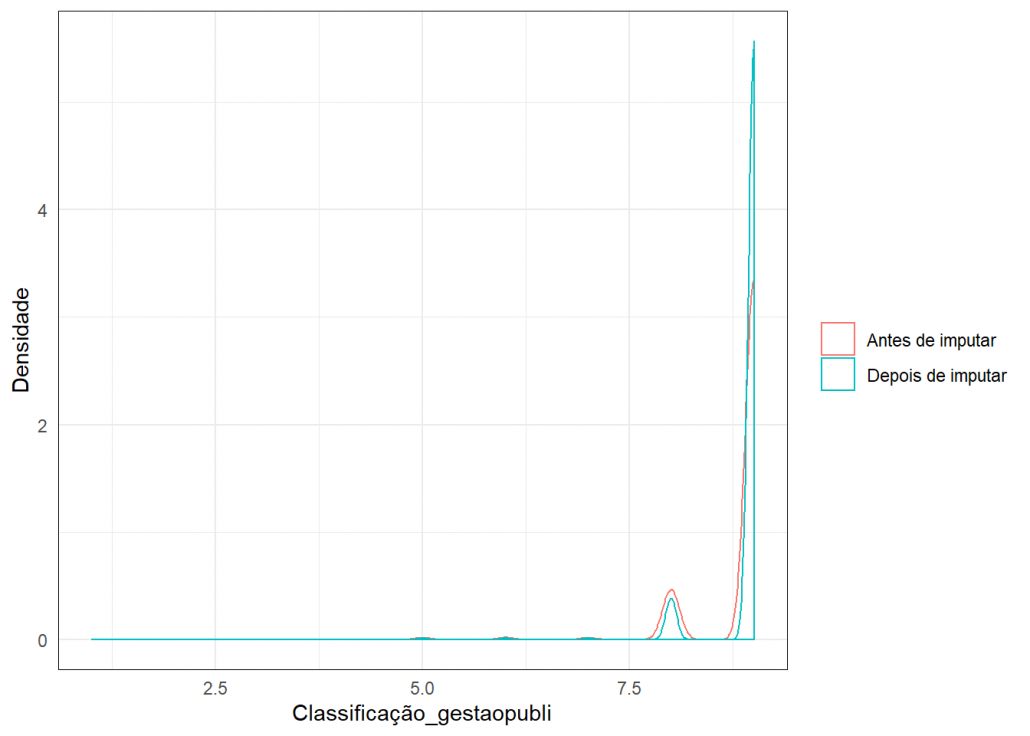
grafico_imput(missing$Empresas_atraídas,dados_completo$Empresas_atraídas,"Classificação_gestaoterrit")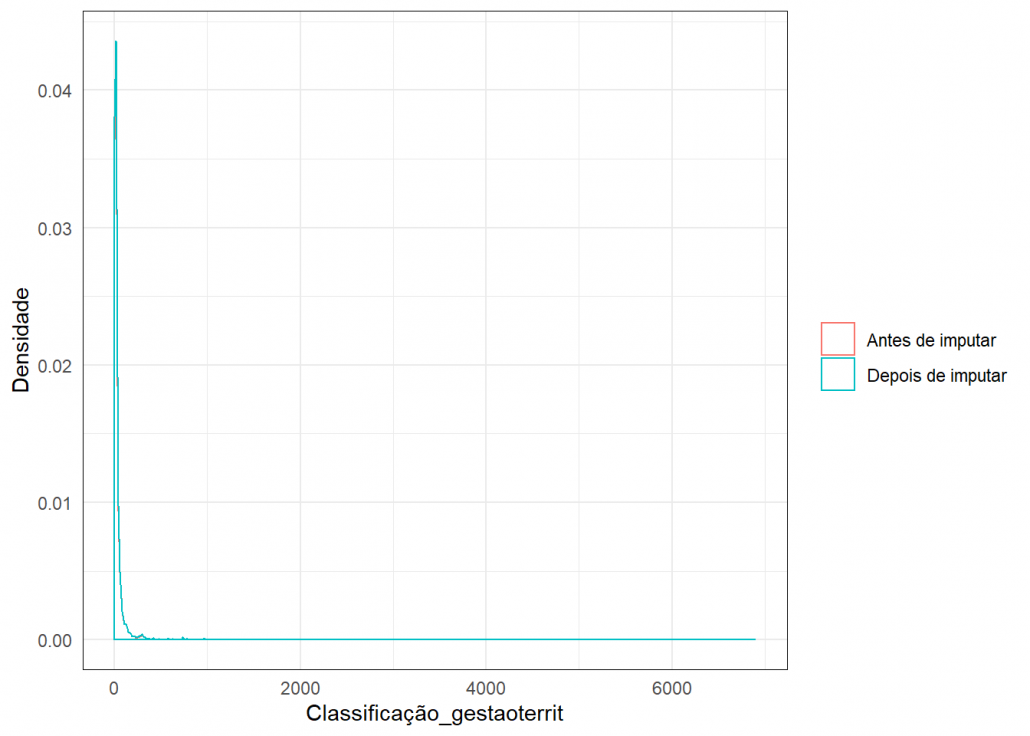
Como as densidades estão bem parecidas, conclui-se que a imputação foi plausível.
Gostou de saber mais sobre o pacote Mice no R? Siga-nos no Instagram, LinkedIn e Facebook para receber as novidades do blog da Oper!


