

Ao analisar uma base de dados, um dos principais desafios do analista é resumir a informação coletada. Em muitos casos, quando contamos com um grande número de observações, pode ser de interesse criar grupos. Dentro de cada grupo os elementos devem ser semelhantes entre si e diferentes dos elementos dentro dos outros grupo.
Por exemplo, suponha que você queira analisar o desempenho do comércio varejista em determinado ano. É sabido que podem existir inúmeros comércios diferentes, mas também sabemos que cada um deles pertence a um segmento específico (vestuário, artigos farmacêuticos, papelaria, etc). É natural pensar que os comércios de segmentos iguais possam ter semelhanças no desempenho, uma vez que atendem a mesma demanda.
Como usar essa importante informação na análise? Uma dos métodos estatísticos que existem para isso é a análise de cluster.
O que é Análise de Cluster?

A análise de cluster é uma técnica estatística usada para classificar elementos em grupos, de forma que elementos dentro de um mesmo cluster sejam muito parecidos, e os elementos em diferentes clusters sejam distintos entre si.
Para definir a semelhança – ou diferença – entre os elementos é usada uma função de distância, que precisa ser definida considerando o contexto do problema em questão.
Podemos dividir a análise de cluster em dois grandes tipos de métodos: hierárquicos e não hierárquicos.
Métodos Hierárquicos
Os métodos hierárquicos da análise de cluster tem como principal característica um algoritmo capaz de fornecer mais de um tipo de partição dos dados. Ele gera vários agrupamentos possíveis, onde um cluster pode ser mesclado a outro em determinado passo do algoritmo.
Esses métodos não exigem que já se tenha um número inicial de clusters e são considerados inflexíveis uma vez que não se pode trocar um elemento de grupo. Eles podem ser classificados em dois tipos: Aglomerativos e Divisivos.
- Métodos Aglomerativos: nesse caso, todos os elementos começam separados e vão sendo agrupados em etapas, um a um, até que tenhamos um único cluster com todos os elementos. O número ideal de clusters é escolhido dentre todas as opções.
- Métodos Divisivos: no método divisivo todos os elementos começam juntos em um único cluster, e vão sendo separados um a um, até que cada elemento seja seu próprio cluster. Assim como no método aglomerativo, escolhemos o número ótimo de clusters dentre todas as possíveis combinações.
Métodos Não Hierárquicos
Os métodos não-hierárquicos da análise de cluster são caracterizados pela necessidade de definir uma partição inicial e pela flexibilidade, uma vez que os elementos podem ser trocados de grupo durante a execução do algoritmo.
O procedimento geral adotado para os métodos não hierárquicos é:
- escolher uma partição inicial (baseada em conhecimentos anteriores do problema);
- realizar o deslocamento do objeto de seu grupo para outros grupos;
- verificar o valor do critério utilizado, decidindo pela clusterização que apresentar melhoria.
Esse processo é repetido até que não se obtenha mais nenhuma melhoria com os deslocamentos. Os métodos das k-médias e o Fuzzy c-Médias são alguns exemplos conhecidos desses métodos, que tem como vantagem a possibilidade de mover um elemento de um cluster para o outro, o que não é possível no método hierárquico.
Usualmente, os métodos não hierárquicos são mais eficientes na análise de bancos de dados com maior número de observações.
Aplicação da Análise de Cluster
Para exemplificar a análise de cluster, usaremos um banco de dados retirado da revista 1974 Motor Trend US magazine, que possui 10 variáveis referentes ao design e a performance de 32 automóveis. A fim de agrupar os carros que foram similares quanto ao desempenho e design, foi feita uma Análise Hierárquica de Cluster, utilizando o Método de Ward a partir da distância Euclidiana.

Dendograma – Visualizando a Análise de Cluster
Usa-se o dendograma para visualizar o processo de clusterização passo a passo, assim como analisar os níveis de distância dos clusters formados. Um bom ponto de decisão da clusterização final é onde os valores de distância mudam consideravelmente. Para a decisão do agrupamento final também devem ser avaliados se os clusters formados fazem sentido para o problema.
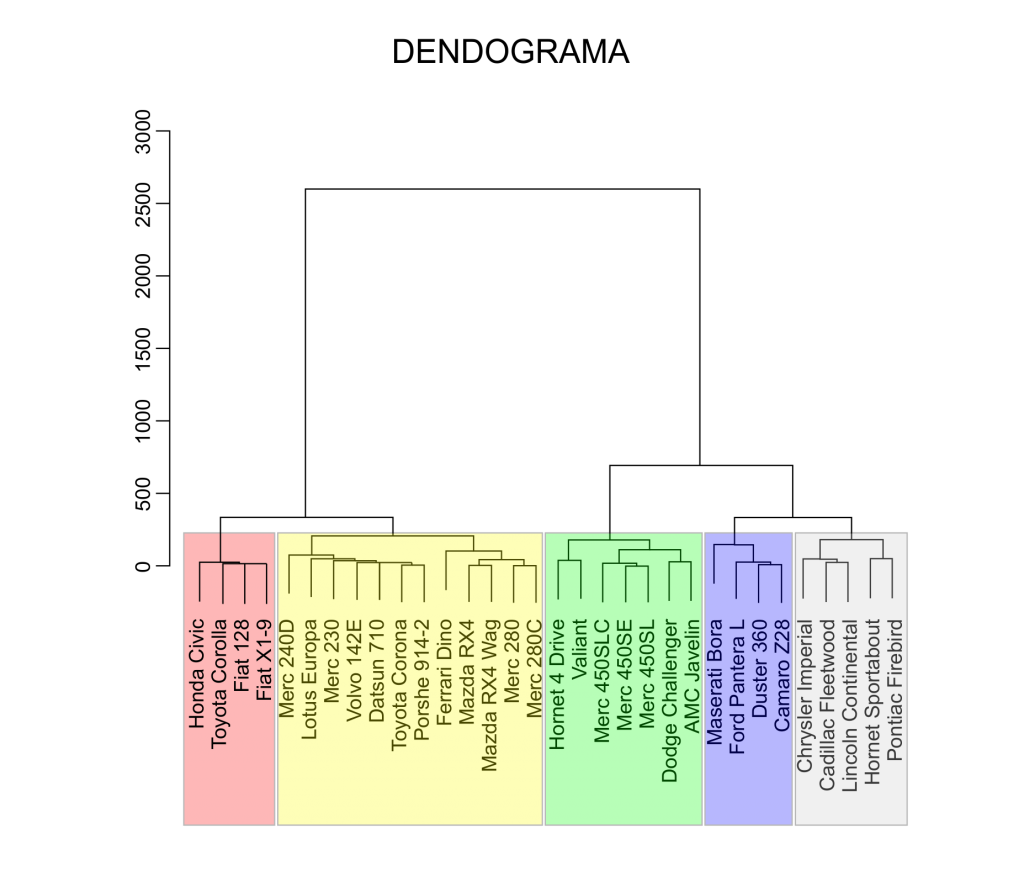
Para a análise dos dados de automóveis, optou-se por um agrupamento final com 5 clusters, uma vez que observamos um salto considerável na distância do passo anterior para esse. Assim, ficamos com 5 grupos, cada um contendo de 4 a 12 carros.
Como fazer Análise de Cluster?
A maioria dos ambientes e softwares de análise estatística possuem opções para realizar a análise de cluster e a construção de dendogramas. O software R possui uma grande quantidade de funções e pacotes para se trabalhar com análise de agrupamento.
Em futuros artigos iremos apresentar métodos para definir o número de grupos em uma análise de cluster e para calcular o valor-p em cada etapa de um processo de agrupamento hierárquico.
Não deixe de se inscrever em nosso blog para acompanhar nossas publicações. E caso tenha alguma dúvida sobre como aplicar a análise de cluster em seu projeto, entre em contato com nossos consultores.
Artigo desenvolvido com a colaboração de Camila Ribeiro.



7 comentários em “O que é Análise de Cluster?”
Pingback: Análise de cluster – Monolito Nimbus
Olá! Esse tema me interessa muito! Agradeço se puderem avisar quando os próximos textos saírem!
Obrigada!
Oi Sofia!
Segue a gente nas redes sociais, estamos no Facebook, no Instagram e no LinkedIn.
Sempre avisamos por lá quando tem conteúdo novo no blog!
Excelente conteúdo.
Valeu Tiago!
Olá pessoal! Tenho interesse no assunto e como desenvolver um cluters.
Bom dia, Claudete!
Para desenvolver um cluster para análise de clusters, siga estes passos:
1. Escolha as variáveis relevantes.
2. Normalize os dados.
3. Escolha o algoritmo de clusterização mais apropriado.
4. Defina o número de clusters.
5. Execute o algoritmo nos dados normalizados.
6. Avalie a qualidade dos clusters gerados.
7. Interprete os clusters e extraia insights.
Lembre-se de que a análise de clusters é um processo iterativo e pode ser necessário ajustar alguns dos parâmetros mencionados acima para obter os resultados desejados.